Artificial Intelligence has a potentially disruptive impact on organizations, firms, and society at large. The latest mind-boggling illustration came with the discovery of chatGPT’s mesmerizing results in November 2022. This followed a fall of investments in AI last year in Silicon Valley. From analyzing data in one’s business to increasing customer engagement and replacing humans in routine tasks across industries, AI is becoming more relevant to our lives and economy every day. Everyone talks about it, but do we really understand its opportunities and threats? And how can we make the best out of it, whilst ensuring that ethical requirements are met?
Structure
Part 1
Make AI Your Ally: Editorial
Artificial Intelligence has a potentially disruptive impact on organizations, firms, and society at large. The latest mind-boggling illustration came with the discovery of chatGPT’s mesmerizing results in November 2022. This followed a fall of investments in AI last year in Silicon Valley. From analyzing data in one’s business to increasing customer engagement and replacing humans in routine tasks across industries, AI is becoming more relevant to our lives and economy every day. Everyone talks about it, but do we really understand its opportunities and threats? And how can we make the best out of it, whilst ensuring that ethical requirements are met?
Part 2
What Machine Learning Can Teach Us About Habit Formation
How long does it take to form a new habit, whether starting a yoga routine or flossing after brushing teeth? A wide-ranging study by Anastasia Buyalskaya from HEC Paris, Hung Ho of the University of Chicago, Xiaomin Li and Colin Camerer of California Institute of Technology, and Katherine L. Milkman and Angela L. Duckworth of the University of Pennsylvania, applies machine learning to answer that question.
Three key facts:
Machine learning: The study uses large datasets and machine learning to uncover the diverse contextual variables influencing habit formation.
Debunking the 21-days myth: There is actually not a fixed timeframe to establish new habits.
Context matters: Certain variables had very little effect on the formation of a habit, whereas other factors turned out to matter a lot.
Part 3
Bridging Sustainable Supply Chains with AI
When it comes to the renewable energy transition, all actors in the supply chain have different stakes, incentives and barriers. HEC Paris Professor Sam Aflaki aims to help organizations contribute to this renewable energy transition in the fields of supply chain management, sustainability and energy efficiency. In this interview, he discusses his ongoing research, exploring the dynamics of stakeholders' incentives, technological advancements, and the challenges shaping sustainable practices in today's world.
Part 4
AI Can Level Global Playing Field
Artificial Intelligence is revolutionizing all fields of business, forcing academics and practitioners to revise their fundamentals. To discuss these new challenges, HEC Associate Professor Carlos Serrano and his colleague Thomas Åstebro organized a groundbreaking workshop inviting some of the world’s top researchers to compare their approach to those of leading industrialists. In our latest Breakthroughs, we discuss some of the takeaways with Serrano, an academic in the school’s Department of Economics and Decision Sciences.
Part 5
Taking The Help or Going Alone: Students Do Worse Using ChatGPT
How good are students at using tools like ChatGPT? In particular, can they properly evaluate and correct the responses provided by ChatGPT to enhance their performance? An experiment on HEC Paris students set to find out. Its results contribute to the debate on the consequences of the use of ChatGPT in education, and in work in general.
Part 6
How AI Can Help Figure Out When Hospital Patients Need Intensive Care
When hospital patients unexpectedly take a turn for the worse and must be transferred to the intensive care unit (ICU), they are more likely to die or must spend a longer time in the hospital. But research by Julien Grand-Clément, Assistant Professor in Information Systems and Operations Management at HEC Paris and chair holder at the Hi! PARIS Center, and colleagues in the U.S. from Columbia University and the Kaiser Permanente Northern California Division of Research, suggests that a mathematical model commonly used in Artificial Intelligence (AI) can help doctors predict patients’ decline and transfer them to the ICU proactively, before their health condition deteriorate critically.
Part 7
Nudges and Artificial Intelligence: for Better or for Worse?
The latest developments in artificial intelligence are often allied to the prospect of a better world, with more powerful, more rational algorithms straightening out human flaws. The idea often floated is that public policy will be more effective because it will be better informed and more responsive. Likewise, it is said that medicine will deliver speedier, more accurate diagnoses. But where are we when it comes to the subject of consumption? Can algorithms be used to steer consumers towards better, more enlightened – and less impulsive – choices? Why not? Online assessments about a product or service, for instance, help information flow more smoothly. But we are also heading down a new path: myriad algorithms are now the power behind “nudges”, those fine details about the shopping environment that insidiously guide the choices made by consumers.
Part 8
Future of Finance: How Are New Technologies Reshaping the Sector?
The advent of digital technologies has created a very new and vastly different financial landscape. Today's buying and selling of securities is conducted mostly by computer programs that react within nanoseconds – faster than any human could – to the subtlest market fluctuations. In a new report published by the Centre for Economic Policy Research (CEPR), Professor of Finance Thierry Foucault comes to grips with how technologies are fundamentally changing the way banks, brokers, exchanges, and dealers do their work, and what it means for investors, for privacy and income inequalities.
Part 9
HEC Research Points to AI Solutions to Prevent Miscarriages of Justice
In the United Kingdom, more than 700 Post Office workers were wrongfully convicted of theft, fraud and false accounting between 2000 and 2014. That was the result of a fault in Horizon, a Fujitsu computer system used by the UK Post Office. How can AI solutions be developed to detect and prevent such intelligent anomalies? To answer these questions and more we have turned to HEC Professor of Accounting and Management Control, Aluna Wang. She is also chairholder at Hi! PARIS Center on Data Analytics and Artificial Intelligence.
Part 10
To What Extent Do People Follow Algorithms’ Advice More Than Human Advice?
Algorithms can enable faster, more effective decision making in domains ranging from medical diagnosis to the choice of a romantic partner. But for this potential to actually translate into useful practical choices, humans must trust and follow the advice algorithms provide. Researchers in Information Systems Cathy Liu Yang and Xitong Li of HEC Paris and Sangseok You of Sungkyunkwan University, have explored the factors that influence people's reliance on algorithmic decision aid.
Part 11
How Do Algorithmic Recommendations Lead Consumers to Make Online Purchases?
Many E-commerce sites such as Amazon, YouTube, and Netflix, but also online advertisers, use recommender systems. Recommender systems are algorithms that, based on data sets, recommend to users contents and products that match their preferences. In this interview, Xitong Li of HEC Paris, Associate Professor of Information Systems and a Hi! PARIS center’s research fellowship holder, reveals new research, a joint work with two German researchers, and explains how recommender systems induce consumers to buy.
Part 12
AI in HR: How is it Really Used and What are the Risks?
Artificial intelligence has only recently been taken on board by human resources, and only after being introduced into other fields. Where do we stand in concrete terms? Although there has been a whole host of ingenious innovations (driven on by start-ups in particular), and although everything virtual is all the rage, the technology seems to run up against serious limits when it comes to HR. Based on a survey carried out among HR managers and digitalization project managers working in major companies, I recall three potential pitfalls regarding the data used, the risk of turning AI into a gimmick, and algorithmic governance.
Part 13
Understanding AI-Human Interactions to Foster Creative Effort
What comes out of our collaborations with artificial intelligence? What happens in the minds of humans who are involved in interactions with smart non-humans? Does AI change how we come up with new ideas and work together on bringing them into life? Daria Morozova, Ph.D. student at HEC Paris’s Management and Human Resources department, explains how her research on AI-human interactions can help establish best practices for creative work involving artificial intelligence.
Part 14
Meta and Data Privacy: a Clash of Cultures and Generations?
HEC Paris Assistant Professor in Marketing, Klaus Miller, analyzes the February 3 Facebook/Meta stock market plunge. What exactly does it tell us about private data on internet and its links to the advertising world? We meet Klaus on February 8, the very day he and five co-researchers self-published “The Impact of the GDPR on the Online Advertising Market”. This book focuses on Europe’s GDPR and how it affects online publicity. In a wide-ranging discussion on personal data and the advertising industry, Klaus provides insights on ad blockers on news websites and their impact on our reading habits.
Part 15
“A $%^* Sexist Program”: Detecting and Addressing AI Bias
A major issue facing companies that use AI, algorithmic bias can perpetuate social inequalities — as well as pose legal and reputational risks to the companies in question. New research at HEC Paris offers a statistical method of tracking down and eliminating unfairness.
Part 16
Developing an Automated Compliance App to Help Firms Comply with Privacy Regulations
According to recent research published by the Harvard Business Review, a strong privacy policy can help firms save millions. If privacy policies have indeed become more important for firms and consumers today, the real challenge lying ahead is to ensure compliance within and beyond the firm. A new tool developed at HEC Paris uses artificial intelligence to help managers, data protection officers, and project leaders take privacy-preserving decisions and implement privacy by design.
Part 17
How Should We Design the Next Generation of AI-Powered Chatbots?
Have you been enraged by a chatbot recently? Businesses from Starbucks to LinkedIn and Singapore Airlines to eBay are embracing AI-powered communication tools. But the success of using chatbots to streamline operations and deliver consistent, round-the-clock customer support hinges on gaining user trust, show recent findings from HEC Paris Professor Shirish Srivastava and his co-authors Dr. Shalini Chandra of the SP Jain School of Global Management, Singapore and Dr. Anuragini Shirish of the Institut Mines Telecom Business School, France.
Part 18
Will the Increased Use of AI in Private Equity Cause an Industry Shakeout?
A new study developed by Thomas Åstebro, Professor of Entrepreneurship at HEC Paris, finds that the number of private equity (PE) and venture capital (VC) firms using artificial intelligence has increased dramatically in the past decade. The study claims that while increasing efficiency overall, AI will also change deal-making processes and destroy junior-level jobs. This article summarizes the article, ‘An Inside Peek at AI Use in Private Equity’, published in the Journal of Financial Data Science (Summer 2021, jfds.2021.1.067) with Portfolio Management Research (PMR).
Artificial Intelligence has a potentially disruptive impact on organizations, firms, and society at large. The latest mind-boggling illustration came with the discovery of chatGPT’s mesmerizing results in November 2022. This followed a fall of investments in AI last year in Silicon Valley. From analyzing data in one’s business to increasing customer engagement and replacing humans in routine tasks across industries, AI is becoming more relevant to our lives and economy every day. Everyone talks about it, but do we really understand its opportunities and threats? And how can we make the best out of it, whilst ensuring that ethical requirements are met?
To be a leading actor in the AI revolution, HEC Paris is active on two fronts: on the teaching side, we have set up with École Polytechnique, the MSc Data Science for Business, which is ranked third in the world. Other programs at HEC also feature a growing number of classes on coding, data science, and on the strategic value of data in companies.
On the research front, HEC Paris has joined forces with the the Institut Polytechnique de Paris and Inria to create the Hi! PARIS Center. The Center conducts multidisciplinary research on AI and its applications to business and society, and develops groundbreaking education programs on these topics. The ambition of this newly-opened center is to become a world-class hub and a destination of choice for students and faculty. It seeks to guarantee that AI and data empower business and society, providing essential resources for companies and laboratories, both public and private, and strengthening France and Europe’s leadership positions.
In this In-Depth special, you can find the latest key findings by HEC Paris researchers, including the Hi! PARIS Center’s chair holders and fellows, from the various disciplines ranging from Economics and Decision Sciences to Finance, Accounting and Management Control, Information Systems and Operations Management, Human Resources, and Marketing.
The researchers unveil techniques and opportunities offered by complex systems, but also warn about the consequences engendered by a lack of understanding and regulation. While they are very diverse in terms of topics, HEC research studies on AI share the common goal of combining academic excellence and relevance for companies and society at large. A must-read!
Editors: Nicolas Vieille, HEC Paris Professor of Economics and Decision Sciences and Scientific Co-Director of the Hi! PARIS Center, Christophe Pérignon, Associate Dean for Research and Professor of Finance at HEC Paris, and member of the executive committee of the Hi! PARIS Center, and Céline Bonnet-Laquitaine, Communication & Edition Project Manager for the Faculty & Research at HEC Paris.
How long does it take to form a new habit, whether starting a yoga routine or flossing after brushing teeth? A wide-ranging study by Anastasia Buyalskaya from HEC Paris, Hung Ho of the University of Chicago, Xiaomin Li and Colin Camerer of California Institute of Technology, and Katherine L. Milkman and Angela L. Duckworth of the University of Pennsylvania, applies machine learning to answer that question.
Three key facts:
Machine learning: The study uses large datasets and machine learning to uncover the diverse contextual variables influencing habit formation.
Debunking the 21-days myth: There is actually not a fixed timeframe to establish new habits.
Context matters: Certain variables had very little effect on the formation of a habit, whereas other factors turned out to matter a lot.
If you’ve ever tried to get in shape, you know how difficult it can be to develop a regular exercise habit. At first, just changing into your workout clothes and getting yourself to the gym seems to take an inordinate amount of effort, and the actual exercising may feel uncomfortable and awkward. But gradually, if you stick with it, you not only see improvement in your physical condition, but even begin to look forward to your regular workouts.
A popular myth says that if you stick with a new behavior for 21 days, it becomes permanent, but this isn’t based on scientific research.
But how long does it take to make exercising a habit? There’s a popular myth that if you stick with a new behavior for 21 days, it becomes permanent, but that guestimate isn’t based on scientific research. That’s why I and my colleagues at several U.S. universities decided to investigate the subject of habit formation using a powerful tool—machine learning, a branch of AI and computer science which utilizes data and algorithms to mimic the way that humans learn. Our paper marks the first time that machine learning has been used to study how humans develop habits in natural settings.
Our paper is the first to use machine learning to study how people form habits in real-world situations.
What we learned about habit formation refuted popular wisdom. As it turns out, it appears that there isn’t a single magic number of days, weeks or months for establishing a new habit. To the contrary, when we studied the development of two different behaviors, we found very different time spans were required for each one to become predictable. Exercising appears to take several months to become habitual. In contrast, handwashing – the other behavior we analyzed - is predictably executed over a much shorter time span, a few days to weeks.
How we studied gym goers and hand-washers
In the past, one of the limitations of habit research has been that researchers have depended upon participants filling out surveys to record what they do, a methodology that typically limits sample size and may introduce noise. In our research, by using large datasets that rely on automatically recorded behavior—for example, exercisers swiping their badges to enter a fitness center—and then using machine learning to make sense of the data, we were able to study a larger group of people over longer time periods in a natural environment.
In addition, by using machine learning, we don’t necessarily have to start with a hypothesis based upon a specific variable. Instead, we’re able to observe hundreds of context variables that may be predictive of behavioral execution. Machine learning essentially does the work for us, finding the relevant predictors.
To study exercisers’ habit formation, we partnered with 24 Hour Fitness, a major North American gym chain, to study anonymized data about gym use. Our dataset spanned a 14-year-period from 2006 to 2019, and included about 12 million data points collected from more than 60,000 users who had consented to share their information with researchers when they signed up to be in a fitness program. We were able to look at a long list of variables, ranging from the number of days that had elapsed between visits to the gym, to the number of consecutive days of attendance on the same day of the week. We whittled down the participants to about 30,000 who had been members for at least a year, and studied their behavior from the first day that they joined the gym.
To study hospital workers’ formation of hand-washing as a habit, we obtained data from a company that employed radio frequency identification (RFID) technology to monitor workers’ compliance with sanitary rules. Each data point had a timestamp, as well as anonymized hospital and room locations. This enabled us to look at the behavior of more than 3,000 workers in 30 hospitals over the course of a year.
What affects habit formation
We discovered that certain variables had very little effect on the formation of a habit, whereas other factors turned out to matter a lot. For example, for about three-quarters of the subjects, the amount of time that had passed since a previous gym visit was an important indicator of whether they would show up to the gym. The longer it had been since they’d worked out, the less likely they were to make a habit of it. Additionally, we found that the day of the week was highly predictive of gym attendance, with Monday and Tuesday being the strongest predictors.
We discovered that certain variables had very little effect on the formation of a habit, whereas other factors turned out to matter a lot.
We also studied the impact of the StepUp Challenge, a behavioral science intervention intended to increase gym attendance, whose designers included two of the researchers on our team. That analysis yielded an interesting insight. The motivational program had a greater effect on less predictable gym-goers than it did on ones who had already established a regular pattern, echoing a finding in the habit literature that habits may make people less sensitive to changes in rewards.
With hospital workers and hand-washing, we discovered that habit formation came more quickly—usually within about two weeks, with most hospital staff forming habits after nine to 10 hospital shifts. The most important predictor of hand-washing was whether workers had complied with hand-washing rules on the previous shift. We also found that 66 percent of workers were influenced by whether others complied with hand-washing rules, and that workers were most likely to wash their hands upon exiting rooms rather than when they entered them.
That raises the question: Why did workers develop the hand-washing habit so much more quickly than gym goers developed the workout habit? One possible explanation is that compared to hand-washing, going to the gym is a less frequent and more complex sort of behavior. Hand-washing is more likely to involve chained sensorimotor action sequences, which are more automatic. Once you get in the habit of washing your hands, you may do it without even thinking. Going to the gym, in contrast, is something that still requires time, planning and intention, even after it’s become a familiar part of your lifestyle.
The study analyzed how people form habits in natural settings. It is relevant for businesses looking to create “habit-forming” products for consumers, and managers looking to instill good habits in their employees.
Methodology
To get a better understanding how habits develop in natural settings, the researchers developed a machine learning methodology that was suitable for analyzing panel data with repeated observations of behavior. They utilized a Predicting Context Sensitivity (PCS) approach, which identified the context variables that best predict behavior for each individual. PCS uses a least absolute shrinkage and selection operator (LASSO) regression, a hypothesis-free form of statistical analysis which does not pre-specify what variables are likely to be predictive of an individual’s behavior. LASSO generated a person-specific measure of overall behavioral predictability, based on the variables that are predictive of that person’s behavior.
When it comes to the renewable energy transition, all actors in the supply chain have different stakes, incentives and barriers. HEC Paris Professor Sam Aflaki aims to help organizations contribute to this renewable energy transition in the fields of supply chain management, sustainability and energy efficiency. In this interview, he discusses his ongoing research, exploring the dynamics of stakeholders' incentives, technological advancements, and the challenges shaping sustainable practices in today's world.
Photo credits: Mutarusan on iStock
Professor Aflaki, how are you working to make supply chains more sustainable?
I use a multidisciplinary research approach that combines data analytics, operations management, and behavioral science to identify the key leverage points within the supply chain where interventions can have the most significant impact. To do this, I study the incentives and barriers that businesses, policymakers, consumers, and suppliers face when investing in sustainable measures. I also look at how regulatory frameworks can balance sustainability with innovation and growth. Additionally, I examine how consumer behavior can be influenced toward more sustainable choices through information, transparency, and choice architecture redesign.
By leveraging data and analytics, companies can better manage their supply chains, identifying where to improve energy efficiency, invest in renewable energies, and reduce waste.
Our goal is to explore how technology can illuminate the footprint of supply chain activities. By leveraging data and analytics, companies can better monitor and manage their supply chains, identifying areas where improvements can be made in terms of energy efficiency, investment in renewable energies, and waste reduction.
Energy seems to be a central theme in your research…
Absolutely! My research critically examines energy efficiency and the transition to renewables as fundamental components of a sustainable energy shift. Despite the clear economic and environmental benefits of energy-efficient solutions, their adoption rates lag behind their potential. I'm particularly focused on bridging the energy efficiency gap, exploring how data analytics and strategic contracting can encourage the adoption of energy-efficient technologies, moving us closer to net-zero targets. This research, entitled “Performance-Based Contracts for Energy Efficiency Projects,” is funded by donors of the HEC Foundation’s Research Committee, who I would like to thank.
Your research on renewable energy was just published in the Harvard Business Review*, and received a lot of attention. What challenges does this sector face, and how does your research overcome them?
In addition to energy efficiency, a sustainable energy transition requires investment in renewable sources of energy. In this research, we focus on the renewable energy sector, particularly offshore wind energy. We investigate the delicate balance between maximizing energy production and mitigating environmental impacts. While it is essential to move towards renewable energy sources, there is a risk of overlooking the long-term environmental consequences, such as waste management and the lifecycle footprint of renewable technologies. Based on the lessons we've learned from past technological rushes, like the e-waste crisis, our research advocates for a more nuanced approach. Our research advocates for a lifecycle approach to renewable technology development, ensuring we don't overlook long-term environmental costs in the rush toward renewables.
In supply chain management, what specific challenges are you focusing on?
Supply chain management is undergoing significant transformation due to the tightening of due diligence regulations worldwide. These rules demand greater accountability and transparency from companies through all supply chain levels, not just with direct suppliers. We examine how the relative bargaining power between suppliers and buyers influences the design of these legislations.
Navigating this shift is complex, as it involves understanding the dense network of global supply chain relationships, which span diverse legal and compliance landscapes.
Yet, this complexity also opens doors for innovation in supply chain management. Digital technologies, particularly data analytics and blockchain, are pivotal in ushering in a new era of transparency and accountability. Blockchain, for example, enables the creation of secure, immutable records, offering unprecedented traceability and verification capabilities across the supply chain.
This is where data analytics and AI can be useful to navigate these supply chain challenges, right?
Indeed! AI and machine learning are game changers, improving supply chain forecasting, risk evaluation, and compliance. These technologies offer insights that can significantly enhance supply chain sustainability, including improved forecasting of disruptions, better evaluation of supplier risks, and enhanced social and environmental compliance. For instance, AI tools can process large datasets to forecast disruptions and highlight ethical concerns with suppliers, which is crucial for enhancing the resilience and sustainability of the supply chain. This would allow companies to have less exposure toward non-compliance penalties enforced by due diligence legislation.
Can you provide a detailed case study where these technologies have been successfully applied?
The use cases are extremely diverse and effective. A cool example of this application is the initiative by CMA CGM, for which I am honored to hold the HEC Chair on Sustainability and Supply Chain Analytics. I am currently in the process of writing a case about their use of predictive analytics to protect marine life. The company utilizes advanced data analysis to predict the migration paths of whales and adjust their shipping routes accordingly. This initiative demonstrates the potential of predictive analytics in reducing environmental impact.
With the rapid advancement of AI, there is growing concern about its ethical and environmental implications. How do you consider these challenges?
As we harness the power of AI, we must be vigilant about the potential unintended consequences, including the environmental impact of powering AI systems and the ethical considerations around data privacy and algorithmic bias.
My research on investment in renewables advocates for a comprehensive approach that considers their full lifecycle and implications rather than just the immediate benefits. This same approach can be applied to the development and use of AI. It is crucial to consider ethical, environmental, and social impacts from the outset to ensure that our pursuit of technological advancement does not compromise our commitment to sustainability and ethical integrity.
As part of the Hi! PARIS Center, co-founded by HEC, you're at the forefront of research in AI and sustainability. What opportunities does this affiliation provide?
The Hi! PARIS Center is a vibrant hub where academia, industry, and policy intersect, providing a unique platform for interdisciplinary research on the intersection of AI and sustainability. Our collaborative initiatives, such as the Hi!ckathon - a hackathon and several roundtables - we held last December on the impacts and uses of AI in supply chains, demonstrate our commitment to using AI for positive environmental and social outcomes. The center fosters the exchange of ideas and encourages innovations that are technologically advanced yet grounded in sustainability principles. Ultimately, this contributes to a more resilient and efficient global supply chain.
References: Working papers by Sam Aflaki (HEC Paris) and Ali Shantia (Toulouse Business School): “Transparency and Power Dynamics: A Game Theoretic Analysis of the Supply Chain Due Diligence Regulations”, with Sara Rezaee Vessal (ESSEC and HEC alumni); “Performance-Based Contracts for Energy Efficiency Projects”, with Roman Kapuscinski (University of Michigan).
Artificial Intelligence is revolutionizing all fields of business, forcing academics and practitioners to revise their fundamentals. To discuss these new challenges, HEC Associate Professor Carlos Serrano and his colleague Thomas Åstebro organized a groundbreaking workshop inviting some of the world’s top researchers to compare their approach to those of leading industrialists. In our latest Breakthroughs, we discuss some of the takeaways with Serrano, an academic in the school’s Department of Economics and Decision Sciences.
External content from Acast has been blocked.
Access privacy settings
Carlos, you've called the December 2023 workshop “groundbreaking.” As you know, there have been countless conferences of this sort on AI. What makes this one stand out?
Well, something distinctive about our workshop is that from the beginning, we decided not to target academics working on AI only. I wanted to have people with different views. It has been important to me in my life as a researcher to draw inspiration from people from all walks of life. Thomas Åstebro and I wanted to create a connection between researchers and people who were simply curious about the revolutionary change, be they academics or not. The idea was also to have in the same room with us industry experts. Here at HEC, my colleagues have the connections with these industrial kingpins.
The governance of risk and its framework is an interesting area of study that was brought up by the participants.
I found that the industry experts were generally thinking ahead of academics: the long-term questions such as organizational learning, organization of the firm, governance and risk management. These are questions that were brought to the table by industry experts. They wanted to know about research on those topics and some of them said they wish we could have focused more on that in the conference. Take organizational learning, how the gradual digitalization and optional use of AI will increase transparency within the firm. Or the algorithms and how AI and humans cooperate. Leaders like Andrea Pignataro (Founder and CEO, ION,, Ed.) and Dr. Lobna Karoui (President, AI Exponential Thinker, Ed.), thought that this is very relevant and is convinced this is going to have implications on how firms organize themselves. Indeed, the interaction with AI is not only relevant from a theoretical point of view, but also for companies. Then there were discussions on governance and risk management. When you use artificial intelligence or automatized processes, risk gets transformed, it doesn't go away. If everything is done by machines, then you need to have risk management for machines. At the moment, we have a lot of risk management for humans, a lot less for machines. But as we transition into an environment where machines will do a lot more of what we do, we have to rethink on how to manage that risk. So, the governance of risk and its framework is an interesting area of study that was brought up by the participants.
There has been a lot of debate about job loss due to AI’s Large Language Models (LLMs) like ChatGPT. One of your speakers, Pamela Mishkin (from the San Francisco OpenAI company), presented research on the impact on the American labour market, and she concludes that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. How do you respond to such research, Carlos?
By being cautious because what Pamela shows us is the upper limits of how ChatGPT could affect the American workforce. That doesn't mean the humans currently employed for those tasks will be replaced. You have to factor in the cost of adaptation, how effective the AI might be, and how easy it is to implement. It will take a while to really figure it out. And, then, the technology is likely to offer new opportunities, new jobs, new tasks. Nevertheless, it’s a very nice study, a first step towards understanding the labor implications. But it's only the beginning.
Pamela concludes that LLM's could have considerable economic, social and policy implications in the United States, for example. What universal implications are there, that can be extrapolated towards Europe, Asia or beyond?
So, putting aside these consequences and whether they might be positive or negative, there is a big difference between now and when the Internet arrived. In my early 20s, access to the Internet, needed a computer. It was expensive to access the Internet with a good connection. And you also need the hardware you know, modems, etcetera. So it wasn't accessible for many people even in Western nations, much less in developing countries. This, it’s different. For better or for worse, we have fast Internet connections, through cell phones or on home computers. And in terms of language, you don't need to know computer science or anything like that. You can interact with the LLMs as long as you’re literate. And you don't need to know English alone. You can actually interact in your own language, French, Spanish, even vernacular languages. So, the benefits will not necessarily stay in the United States. This is the first time, that there’s a level playing field. Everyone is having access to this. You know whether you are at HEC in the office or in rural settings worldwide, where traditionally access to technology is more challenging.
This was one of many topics hotly debated at the workshop which explored a diversity of issues. They ranged from a study on Generative AI and human crowdsourcing to exploring how cost effective it would be to automate human tasks with AI. Your own research has been on patents, their market, their value and use. But in what research have you used the juncture between AI and entrepreneurship? And what links can you establish with patents or your other research interests like the strategy and financing of entrepreneurial activities?
OK, so people have been using machine learning and the study of the economics of innovation, especially in relation to patents and patent landscapes, for a while. It’s a topic of interest for corporates and consultants. Patent landscapes predict technological trends, so researchers have been studying this for a while, using this tool to refine existing measures of similarity between patent portfolios of companies. For instance, these techniques can be useful to assess the synergistic value between acquirers and potential targets and markets for technology. However, what I find really interesting is when the new technology opens up the possibility to investigate an area that, in the absence of such technology, would have been otherwise impossible or extremely hard to carry out. What excites me is that this new technology, especially large language models like Chat GPT applications, allows us to quickly process massive amounts of text. And this can be a game changer. For instance, the interaction between the inventors and patent examiners determines if an invention in a patent application is truly noble. We use a lot of text, there's a lot of data. So, access to artificial technology and other new tools will allow us to actually dig down into that documentation. It has the potential for us researchers to understand what innovations truly innovate. It also helps us to better understand the process. And, finally there is the potential for the patents office to improve, to make the processing of patent applications faster.
How good are students at using tools like ChatGPT? In particular, can they properly evaluate and correct the responses provided by ChatGPT to enhance their performance? An experiment on HEC Paris students set to find out. Its results contribute to the debate on the consequences of the use of ChatGPT in education, and in work in general.
If, as many suggest, ChatGPT-like tools will be central to many work practices in the future, then we need to think about how to design course elements that help today’s students and tomorrow’s professionals learn how to use these tools properly. A correct use will not involve humans copying the output of these tools blindly, but rather them using it as a means to enhance their own performance. Hence the simple question: can students properly evaluate and where necessary correct the responses provided by ChatGPT, to improve their grade in an assignment, for instance? Motivated by such considerations, I designed the following assignment in a first-year Masters level course at HEC Paris.
Answering vs. correcting
Students were randomly assigned two cases, and were asked the same question about each. For the first case, students just had to provide the answer, in the traditional way, ‘from scratch’. For the second case, they were provided with an answer to the question: they were asked whether the answer was fully correct, and told to correct or add as required to make it ‘perfect’. They were told that each provided answer had been either produced by ChatGPT or by another student. In reality, in over 60% of cases, the answer had come from ChatGPT.
Whilst the former, answer task is arguably closer to current work practices, the second correct task may correspond more closely to many jobs in the future, if AI tools become as ubiquitous as many predict.
However, the two tasks asked for the same thing – a full reply to the question concerning the case – and the same grading scheme was used for both. The marks for both tasks counted in equal amounts for the course grade, so students were motivated to make the same amount of effort on both.
On this assignment, students do better without the help of ChatGPT
Nevertheless, the students, on average, got a 28% lower grade on the correct task than on the answer task. For a given case, a student correcting an answer provided by ChatGPT got, on average, 28 marks out of 100 less than a student answering the question by themselves. Students, it turns out, did considerably worse when they were given a ChatGPT aid and asked to correct it than if they were asked to provide an answer from scratch.
Students did considerably worse when they were given a ChatGPT aid and asked to correct it than if they were asked to provide an answer from scratch.
A behavioral bias?
Perhaps these results can be explained by postulating high student trust in ChatGPT’s answers. However, students were explicitly primed to be wary of the responses provided: they had been informed that ChatGPT had been tested on a previous, similar assignment and did pretty badly. And previous research suggests that such information typically undermines trust in algorithms. Moreover, no significant difference was found between their grades on the correct task when they thought they were correcting ChatGPT or another student.
Our classroom experiment suggests that the professionals of tomorrow may do a considerably worse job when aided by AI than when working alone.
A perhaps more promising explanation is in terms of the Confirmation Bias – the tendency to insufficiently collect and interpret information contradicting a given belief or position. Inspection of answers shows a clear tendency among many students to provide small modifications to the provided responses, even where larger corrections were in order. Moreover, there is evidence that this bias tends to persist even when people are warned that the base belief has little claim to being correct 1,2. Could the tendency to display insufficient criticism with respect to certain positions – a bias that is taught in business schools worldwide and HEC in particular – be behind potential misuses of ChatGPT and its alternatives?
Chatbots have been touted as having a future role in aiding humans in a range of areas; but this assumes that humans will be capable of using them properly. One important task for humans in such interactions will be to evaluate, and where necessary correct, the output of their chatbots.
Our classroom experiment suggests that the professionals of tomorrow may do a considerably worse job when aided than when working alone – perhaps due to behavioral biases that have been long understood, perhaps due to some that remain to be further explored.
One of the skills of the future, that we will need to learn to teach today, is how to ensure that ChatGPT actually help.
If anything, this argues for more, rather than less, chatbots in the classroom. One of the skills of the future, that we will need to learn to teach today, is how to ensure that they actually help.
References:
1. Kahneman, D. Thinking, fast and slow. (Macmillan, 2011).
2. Nickerson, R. S. Confirmation Bias: A Ubiquitous Phenomenon in Many Guises. Review of General Psychology 2, 175–220 (1998).
When hospital patients unexpectedly take a turn for the worse and must be transferred to the intensive care unit (ICU), they are more likely to die or must spend a longer time in the hospital. But research by Julien Grand-Clément, Assistant Professor in Information Systems and Operations Management at HEC Paris and chair holder at the Hi! PARIS Center, and colleagues in the U.S. from Columbia University and the Kaiser Permanente Northern California Division of Research, suggests that a mathematical model commonly used in Artificial Intelligence (AI) can help doctors predict patients’ decline and transfer them to the ICU proactively, before their health condition deteriorate critically.
In a hospital, some of the most important resources are beds and specialized nurses in the ICU, where doctors and nurses use advanced technology to save the lives of critically ill patients. But providing that sort of care is complex and expensive, and hospitals can afford to have only a limited number of ICU beds. That shortfall became tragically apparent during the COVID-19 pandemic, when some facilities ran out of capacity to deal with the large number of desperately sick patients. Even in less dire times, doctors still are compelled to make difficult choices, because they can only transfer so many patients to the ICU. At the same time, if they wait until a patient’s health deteriorates to the point where a sudden, unplanned transfer is required, patients’ chances of survival plummet.
But what if doctors had a way to reliably identify the patients whose health was most likely to take a turn for the worse, and proactively send those patients to the ICU? A 2018 research article, relying on nearly 300,000 hospitalizations in the Kaiser Permanente Northern California, provides evidence that proactively transferring patients to the ICU can significantly reduce the mortality risk and length of hospital stays. But there is a risk of going too far. Indeed, other research indicates that if doctors transfer too many patients to the ICU, the ICU may become congested and the survival rate is negatively impacted. In a worst-case scenario in which the ICU is filled to capacity, this could mean that some patients who need ICU care are not able to obtain it.
For a proactive ICU transfer policy to work, three variables are needed: to recalibrate depending upon arrival rates during the day and night, how many nurses you have in the ICU, and whether transferred patients are recovering fast enough. If these metrics are not aligned, you might not make the right transfer decisions.
What we learned by using data to create a simulated hospital
One of my esteemed collaborator, Gabriel Escobar, served as the regional director for hospital operations research at Kaiser Permanente North California in the United States. That provided us with a great opportunity to work with anonymized hospitalization data on 300,000 patients from 21 Kaiser Permanente facilities. We had a tremendous amount of detailed data on cases, right down to things like blood cell counts taken every six hours. Based upon this data, we were able to estimate things such as how patients react to different treatments and various arrival and admission rates to the ICU and the common ward.
With all this information, we were able to build a simulation model, which mimics how an actual hospital works, such as generating arrival and departure rates, the evolution of the patients and every single interaction they have with the system. With this sort of micro-modeling, you can track the simulated patient like you would a real patient during their journey in the hospital. This enables to test different scenarios of arrivals and transfer policies.
In doing our study, we utilized a mathematical model called a Markov Decision Process model, which often is used in AI. In plain English, an MDP is a natural model for sequential decision-making, in which you can inspect a sequence of decisions, and how one choice influences the next one and the overall health outcome. The sequence is influenced only by earlier decisions, not by what you might do down the line--what happens at noon, for example, isn’t affected by what will happen at 3 p.m., because that hasn’t happened yet. But you are influenced by what happened at 9 or 10 or 11 a.m.
The goal is to make the best decisions, not only for each patient but also with the best overall result, that is, the best outcome over the general patient population. We are concerned about the survival of the patient, and at the same time, we want to maintain the ICU occupancy at a reasonable level, so that others do well, and so that unplanned transfers may still be accounted for. We designed an optimization method, based upon machine learning model, to estimate the impact of various transfer policies.
When we ran the model, one surprise was that relatively small adjustments can have a big effect on the mortality of the overall patient population.
When we ran the model, one surprise was that relatively small adjustments in the number of health resources that the system consumes and in the arrival and recovery rates can have a big effect on the mortality of the overall patient population. Given a certain way of transferring patients, we could see the estimated mortality could jump by 20 %.
AI won’t replace human decision making in hospitals
Some people might think that the questions is whether humans should make the decisions about ICU transfers, even though they sometimes make mistakes, or whether algorithms should do it. But as I see it, these two methods are really complementary. At least in the foreseeable future, humans will have the last word. But they are more likely to make those decisions assisted with the recommendations of an algorithm. We want it to be the best automated recommendation system, and it has to provide interpretable insights on its recommendation. If the practitioners are not able to understand where the recommendations come from, they will never use it.
We have to go back the question: what exactly is at stake here? If one patient is transferred to an ICU bed, the patient has better treatment and more nursing, and better survival chance. But at the population level, if the patient transfer is going to cause the ICU to be congested, this becomes a problem for everyone else. What we are doing in this work is to look for simple transfer decision rules, based on common health metrics summarizing the health conditions of the patients and certain thresholds. This type of threshold policy is extremely simple to deploy and readily interpretable.
Using micro-modeling to understand a complicated enterprise and develop algorithms to assist in decision making can lead to better outcomes.
How to Use the Insights: Using micro-modeling to understand a complicated enterprise and develop algorithms to assist in decision making can lead to better outcomes. But it also requires an understanding of variability, and how relatively small changes in the conditions can significantly alter outcomes. Ultimately, it is up to the doctors to make the transfer decisions, but machine learning models may help to assist in the decisions and to provide valuable information regarding the impact of patient transfers.
Methodology
The researchers performed numerical experiments based on a simulation model to compare the performance of both optimal normal and robust ICU transfer policies, using hospitalization data from approximately 300,000 patients from 21 Kaiser Permanente Northern California hospitals.
Applications
The research can help hospitals to develop policies for ICU transfers, which can help more increasing the patients’ survival chance reduce their hospital stays.
This article was based upon an interview with Julien Grand-Clément and the article “Robustness of Proactive Intensive Care Unit Transfer,” published in January 2023 in Operations Research and co-authored with Carri W. Chan and Vineet Goyal of Columbia University, and Gabriel Escobar, research scientist at the Kaiser Permanente Northern California Division of Research and director of the Division of Research Systems Research Initiative.
The latest developments in artificial intelligence are often allied to the prospect of a better world, with more powerful, more rational algorithms straightening out human flaws. The idea often floated is that public policy will be more effective because it will be better informed and more responsive. Likewise, it is said that medicine will deliver speedier, more accurate diagnoses. But where are we when it comes to the subject of consumption? Can algorithms be used to steer consumers towards better, more enlightened – and less impulsive – choices? Why not? Online assessments about a product or service, for instance, help information flow more smoothly. But we are also heading down a new path: myriad algorithms are now the power behind “nudges”, those fine details about the shopping environment that insidiously guide the choices made by consumers.
Nudge theory was developed by Richard Thaler (Nobel Prize in Economics 2017) and Cass Sunstein in 2008. The two authors suggested that cognitive biases (faulty reasoning or perception that distorts decision-making) might serve as an instrument of public policy. These biases could be used to nudge individuals towards decisions that are deemed good for themselves or the wider community – but which they lack the perspicacity or motivation to pursue. Subtle changes in the decision-making environment can steer behaviors in a virtuous direction. Let's say you are staying in a hotel, and you know that most of the previous guests in your bedroom have re-used the same bath towel from day to day; conformity bias will then prompt you to follow suit. This same bias may prod you to cut back on your energy consumption if you find out that it is higher than your neighbor's. Automatically registering voters on the electoral roll – like pre-filled tax returns – is another instance that draws on the virtuous simplification of the target behavior. Nudging is an insidious way of inducing people to change behaviors while safeguarding their freedom of choice. It is an alternative to the conventional tools of state action such as, for example, bans or taxes.
The same methods of influencing people are also employed in marketing based on the following idea: if reason fails to persuade consumers about the utility of a purchase, you can coax them insidiously. Let’s say you want to reserve a hotel online. The site warns you that there are not many bedrooms left in your chosen category, and that other internet users are currently looking at them… all of which nudges you to book your room at full speed so you do not miss out on what you see as a rare opportunity. Websites that display a default purchase option prominently or default acceptance of specific terms and conditions are too numerous to mention. Of course, you are free to disregard these defaults provided you have time on your hands and enjoy a good search. A free trial that you end up paying for because you forgot to cancel it is another example of nudge used for marketing. And then there are those discount vouchers with conditions so limited they never get used, or targeted ads that make well-timed offers. This approach distorts the very nature of nudging since it does not aim to improve the well-being of the consumer or society, which is why it is sometimes known as “bad nudging” or “sludging”.
The prediction made by Noah Harari in 2018 has, worryingly, already come true in part: “As biotechnology and machine learning improve, it will become easier to manipulate people's deepest emotions and desires [...] could you still tell the difference between yourself and [the] marketing experts?” It goes without saying that influence strategies are not exclusive to artificial intelligence. Door-to-door sales reps have known and used more-or-less ethical sales techniques for many years, and it follows that nudges can be employed by humans. Just think of the barista who asks if you would like a pastry – or even a set menu – when all you do is ask for a coffee. And then there is the sales assistant who kicks off negotiations with an inflated offer before pretending to give you a generous discount. Artificial intelligence, however, has the power to swell the use of influence methods by rolling them out systematically on a grand scale. The behavioral biases underpinning standard nudges were derived from experimental research. But big data can automatically detect the tiniest weak point in the decision-making process, which can then be leveraged to influence consumers. Once a new behavioral lever has been identified, algorithms can apply it extensively.
What are the consequences of these “bad nudges”? Consumers may feel deceived because they purchase items or services that do not match their real needs, or because attempts to hold out against the influences generate a fatigue that degrades the shopping experience. Accordingly, using nudges in the field of marketing serves to lower consumer well-being.
In more general terms, the wholesale deployment of nudges often systematizes mistakes that were formerly occasional: irrationality, in other words, becomes the norm.
In other words, irrationality becomes the norm.
In this respect, the growing use of nudges is upsetting the foundations on which liberal economics is built. In this model, it is the pressure exerted by consumers making informed choices that encourages producers to offer products that best match consumer needs at the best price. Nudges upend this process since producers can use them to influence consumer preferences. This means that consumers who have been influenced by nudges no longer exert their counter-power on producers. The possibility that consumer behavior may be swayed by nudging challenges some of the virtues of the market economy. Likewise, the idea that the public might cast their votes under influence undermines the basis of the democratic model.
How can we stave off these damaging effects? Is regulation the answer? It would be problematic to legislate in this area, since the distinction between information and influence is so slight. At the very least, it could become a requirement that the information provided during the purchase process (such as the quantities available) be true, although this would still be difficult to enforce. Change could also be driven by consumers, who could turn their backs on platforms that employ these techniques. This is no easy task: the influences are not always conscious, and some platforms operate a quasi-monopoly. Sellers themselves could also reverse the trend by certifying that they do not use influence techniques as a way of guaranteeing quality and respect for their customers. This approach could be supported by artificial intelligence: algorithms could be used to automatically test online sales sites to detect nudges, and a certification label could be created.
Do we need “good algorithms” for fighting “bad ones”? Although this idea is simplistic, it does remind us that machines only do what we have designed them to do (apart from mistakes in programming). This means that it is up to consumers (or their representatives or advocates) to make use of the possibilities afforded by artificial intelligence to defend their interests.
The advent of digital technologies has created a very new and vastly different financial landscape. Today's buying and selling of securities is conducted mostly by computer programs that react within nanoseconds – faster than any human could – to the subtlest market fluctuations. In a new report published by the Centre for Economic Policy Research (CEPR), Professor of Finance Thierry Foucault comes to grips with how technologies are fundamentally changing the way banks, brokers, exchanges, and dealers do their work, and what it means for investors, for privacy and income inequalities.
Photo Credit: Phongphan Supphakank on Adobe Stock
The 'sell side' industry, concerned with the building up and liquidating of securities portfolios, has undergone enormous changes over the past fifty years, mainly due to the computerization of trading, and more recently the emergence of big data. Those familiar, iconic scenes in which mobs of colorfully garbed brokers tussle and bustle, waving frantically and hollering orders on stock exchange floors, though still sometimes staged for marketing purposes, are a thing of the past.
Two new types of technologies
There are at least two types of technologies driving the so-called 'electronification' of trading. First, exchanges have automated the process by which they match buyers and sellers of securities. Imagine, for example, that you want to buy 1,000 shares of L'Oréal stock. Your bank or broker might send your order to Euronext, one of the exchanges on which L'Oréal is traded. Euronext receives, buys and sells orders like this all the time, using computers and algorithms to match them.
This is already a profound change, but now consider, Euronext is also accumulating massive amounts of data, about submitted orders, about realized transactions and so on, which it can then resell to other intermediaries and investors. In this respect, securities trading platforms are increasingly looking like other digital platforms, like Facebook, Google or Twitter, and the share of their revenues coming from the sale of data is growing very quickly (at an annual rate of about 13% since 2012).
Like Big Tech does, trading platforms could pay you to trade with them, just so you will use their platforms and generate more data!
The second type of technology involves industry participants automating their decisions on the buying or selling of securities. This use of algorithms to make portfolio decisions is what we call algorithmic trading. An asset manager can buy or sell millions of shares of a given stock in a day in response to investors' inflows and outflows in his or her fund. This is the same process of automation that we see in other industries. We are removing humans and replacing them with machines.
Moving fast
Some specialized trading firms, known as high-frequency traders, use algorithms that rely on extremely fast, less-than-a-millisecond, access to information, including to market data sold by electronic trading platforms. With extremely fast access to this kind of market data, these firms can take advantage of small differences in the price of the same stock on two different trading platforms. Some of them pay to have their computer servers housed near trading platform servers – they may even rent rack space in the same room, thus gaining some nanoseconds in the delivery of key information, which can make all the difference.
The question of what effect these developments may have on trading costs for other market participants is controversial, raising many issues that are now at the center of policy debate in the EU and North America.
Questions for regulators: stability and transparency
The European Securities and Markets Authority (ESMA) and various national bodies, such as the Autorité des Marchés Financiers (AMF) in France, are the key regulatory bodies for securities markets in the EU, while the Securities and Exchange Commission (SEC) and the Commodity Futures Trading Commission (CFTC) cover U.S. markets.
A number of issues related to the impact of new technologies are up for consideration by regulators. For instance, does the electronification of financial markets actually reduce the costs at which investors can build and liquidate their portfolios? This could mean far larger returns for investors on their savings. Does algorithmic trading make financial markets more stable, or less so? Do trading platforms have too much market power in the pricing of their market data?
We think the development of central bank digital currencies technology should be targeted at solving market failures.
Another question we address in our report is whether trading should be slowed down. The issue here is that high-frequency traders might be deriving excessive profits, at the expense of other participants.
There is also a concern about trading on platforms with less stringent transparency requirements than the main exchanges. The volume of this so-called 'dark trading' is growing, now accounting for about 40% to 50% of equity trading in the EU, raising debate over whether these platforms should be more strictly regulated. Finally, another issue is to what extent algorithms might destabilize financial markets, resulting in large price swings.
What the future holds
In the coming years, I expect exchanges' business models to continue to rely increasingly on the monetization of data generated by trading. This means exchange platforms will compete with one another to attract users who generate that data, very much like Big Tech does.
The increasing use of consumer data allows for efficiency gains but also involves potential risks in terms of privacy, diminished competition, and increased income inequality.
This trend accelerated during the COVID-19 pandemic, and, if it continues, this will put strong competitive pressures on securities dealers, and it will eventually reduce trading costs for investors. At some point, the data generated by trading may become more profitable than the trading itself. So, there may come a time when trading platforms start to go to greater lengths to attract users. For example, they could simply pay you to trade with them, just so you will use their platforms and generate more data!
The current report is the fourth in the CEPR's 'Future of Banking' series and part of the Banking Initiative launched by the IESE Business School in October 2018 with support from Citi. The goal of the initiative is to study new developments in banking and financial markets. The Center for Economic Policy Research (CEPR) is an independent, non-partisan and non-profit organization, founded in 1983 to enhance the quality of economic policy making in Europe.
Applications
One of the broader messages in the report is about the suitability of central bank digital currencies (CBDCs). We think the development of CBDC technology should be targeted at solving market failures. We also point out that the increasing use of consumer data allows for efficiency gains but also involves potential risks in terms of privacy, diminished competition, and increased income inequality. In short, the electronification of market securities has real policy and economic consequences that we must understand and address.
Based on an interview with Professor of Finance, Thierry Foucault, regarding the CEPR report 'Technology and Finance – Future of Banking 4', co-written with Darrel Duffie from Stanford University, Laura Veldkamp from Columbia University’s Graduate School of Business, and Xavier Vives, from Spain's Instituto de Estudios Superiores de La Empresa (IESE). Find the report here and another summary on VoxEU here.
In the United Kingdom, more than 700 Post Office workers were wrongfully convicted of theft, fraud and false accounting between 2000 and 2014. That was the result of a fault in Horizon, a Fujitsu computer system used by the UK Post Office. How can AI solutions be developed to detect and prevent such intelligent anomalies? To answer these questions and more we have turned to HEC Professor of Accounting and Management Control, Aluna Wang. She is also chairholder at Hi! PARIS Center on Data Analytics and Artificial Intelligence.
They’ve branded it the most widespread miscarriage of justice in the history of the United Kingdom – perhaps the world! The consequences on human lives have been catastrophic and inquiries are ongoing on how to repair them. Experts say the Horizon affair could end up costing the British taxpayer almost €500 million in compensation payments. Nevertheless, after 20 years, the victims have won a legal battle to reverse the verdicts which had led to criminal conviction, prison and fines. So, what does this teach us about the risks of faulty IT systems?
Listen to the podcast:
External content from Acast has been blocked.
Access privacy settings
Doctor Wang, part of your research centers on developing AI tools to improve our understanding of accounting data and proposing intelligent solutions to some real-world challenges in businesses which are undergoing huge changes in the digital world. We saw one of these challenges at the heart of the UK’s Post Office computer scandal. How do you respond to this affair which is the result of a computer system called Horizon, which a High Court judge said was not “remotely robust”?
Aluna Wang: I was certainly shocked by this miscarriage of justice. First of all, we can see that hundreds of Post Office workers were falsely accused of theft and false accounting after Horizon was introduced and incorrectly showed shortfalls on the corporate accounts. If the whole story were told as a movie, even the movie critics would think that the plot was too implausible. It’s tough for me to fathom why the UK Post Office, which is partly owned by the British government, accused so many innocent employees of theft and misreporting rather than explore the possibility that the IT system may be faulty and malfunctioning. Moreover, we don’t see a single high-placed representative from the Post Office, the IT supplier Fujitsu, or Parliament has been truly held accountable for the decisions based on the incorrect information provided by the Horizon system.
As you mentioned earlier, I have experience working with audit partners and banking executives in developing intelligent anomaly detection systems. Usually, they were highly concerned about the false positives generated by the detection systems. Because they know that if they rely on the detection system and the system gives too many false positive alarms, they waste a lot of resources investigating those false-positive cases. In this sense, false positives can be very costly.
They were financially ruined, put out of work, locally shunned, driven into poor health, and saw their families destroyed.
But here, in this Post Office scandal, we see that without rigorous monitoring of the IT system, and serious investigations into the alarms raised by the IT system, there could be even more severe costs to society. More than 700 Post Office workers were wrongfully prosecuted. Their lives and the lives of thousands of others were torn apart. They were financially ruined, put out of work, locally shunned, driven into poor health, and saw their families destroyed. This whole incident made me think more about not only the design and deployment of IT systems and AI solutions, but also how to manage the risk of using those technological solutions and how to build accountability into those solutions.
With hindsight, what could have been done to prevent such errors?
There are undoubtedly many things that could have been done to prevent this scandal. I would like to speak more from the risk management perspective. The UK Post Office could have set a clear tone at the top regarding the transparency and integrity of the IT systems put into place. It could have conducted a thorough investigation of any potential defects in the Horizon system before signing the contract with Fujitsu and made a robust risk management and monitoring plan of the Horizon system after implementing it.
Moreover, the Post Office should have taken a whistleblower, Alan Bates, more seriously. Bates reported the problems linked to the Horizon system to the Post Office management team in the early 2000s. Unfortunately, his reports were not only taken seriously but his contract with the Post Office was terminated.
Given my field of research, I actually think one of the AI solutions I developed with my collaborators can be helpful in this case. We have been working on an anomaly detection system designed for internal audit, risk management, and compliance purposes.
We have been working on an anomaly detection system designed for internal audit, risk management, and compliance purposes.
When you put accounting data into the detection system, it can assign anomaly scores to each financial transaction. It tells you why certain transactions or patterns of transactions are anomalous based on the metadata and the accounting structure of transactions. In this case, our detection system should be able to detect the changes in transaction patterns after implementing the Horizon system and flag many of the incorrect records generated by the Horizon system as highly anomalous. Furthermore, our algorithm can also generate explanations concerning how the anomaly scores were assigned based on the algorithm’s logic.
But still, we would need the Post Office management to take the red flags of the Horizon system seriously and investigate accordingly. After all, this miscarriage of justice is not only about a flawed IT system, but also about how the Post Office deals with it.
Also, since this scandal concerns severe legal enforcement actions, I think there is also a lesson for Fujitsu and other tech companies. Fujitsu should not only be more effective in reducing product defects but also look at how its clients are using the output of its systems. Horizon is a point-of-sale system that records transactions, but the Post Office also uses the data output for prosecutions. More attention should have been paid to the data output at that point. Perhaps, Fujitsu should not have handed over data packs to the UK Post Office as court evidence.
Finally, Dr. Wang, could you share with us some of the latest research you are conducting in the Hi!PARIS context? After all, your explorations involve developing machine learning-based tools to improve our understanding of accounting data, research that seeks intelligent solutions to real-world challenges like the ones we saw in the UK Post Office affair…
Our Hi! PARIS center is a research center for science, business, and society. It really aims to combine the expertise of people from different fields of specializations to address important questions at the intersection of science, technology, and business, while developing new education programs and fostering innovation.
I personally would like to put AI research into three categories: the first one is about “AI solutions”, which is what you called “intelligent solutions”. For this type of research, we engineer AI solutions addressing business and societal problems. For example, my collaborators and I have designed algorithm packages for risk management of financial institutions. Our graph-based machine learning algorithms can be used for anti-money laundering, email communication monitoring, and fraud detection purposes.
Our graph-based machine learning algorithms can be used for anti-money laundering, email communication monitoring, and fraud detection purposes.
I would like to call the second category “AI for Social Science”. We can leverage AI techniques to understand better economic phenomena. For instance, my collaborators and I are currently working on using graph mining techniques to investigate the knowledge spillover in the open-source community.
And, finally, I call the third category of research “Social Science for AI”. For this type of research, we can use our social science research methods to examine how AI and digital transformation affect our human behaviors and business models. My collaborators and I are currently working on analyzing the human-algorithm interactions on the social platforms and figuring out how we can design algorithms to improve the information environment of social platforms.
Algorithms can enable faster, more effective decision making in domains ranging from medical diagnosis to the choice of a romantic partner. But for this potential to actually translate into useful practical choices, humans must trust and follow the advice algorithms provide. Researchers in Information Systems Cathy Liu Yang and Xitong Li of HEC Paris and Sangseok You of Sungkyunkwan University, have explored the factors that influence people's reliance on algorithmic decision aid.
Photo Credits: Have a nice day on Adobe Stock
Machine recommendations result in 80% of Netflix viewing decisions, while more than a third of purchase decisions on Amazon are influenced by algorithms. In other words, algorithms increasingly drive the daily decisions that people make in their lives.
It isn’t just consumer decision making that algorithms influence. As algorithms appear increasingly in different situations, people are using them more frequently to make more fundamental decisions. For example, recent field studies have shown that decision makers follow algorithmic advice when making business decisions or even providing medical diagnoses and releasing criminals on parole.
Do people prefer human or machine advice-giving?
People regularly seek the advice of others to make decisions. We turn to experts when we are not sure. This provides us with greater confidence in our choices. It is clear that AI increasingly supports real-life decision making. Algorithms are ever more intertwined with our everyday lives. What we wanted to find out is the extent to which people follow the advice offered by AI.
To investigate the matter, we conducted a series of experiments to evaluate the extent to which people follow AI advice. Our study showed that people are more likely to follow algorithmic advice than identical advice offered by a human advisor due to a higher trust in algorithms than in other humans. We call this phenomenon “algorithm appreciation”.
Higher Trust in AI… but don’t go overboard on information
We wanted to find out more, to see if people would follow AI advice even if the AI is not perfect. Our second series of experiments focused on exploring under which conditions people might be either more likely or less likely to take advice from AI. We engineered experiments that tested whether people would have greater trust in algorithms even when they were aware of prediction errors with the underlying AI.
Surprisingly, when we informed participants in our study of the algorithm prediction errors, they still showed higher trust in the AI predictions than in the human ones. In short, people are generally more comfortable trusting AI than other humans to make decisions for them, regardless of known and understood imperfections in the process.
People are generally more comfortable trusting AI than other humans to make decisions for them, regardless of known and understood imperfections in the process, except when there is too much information about the algorithm and its performance.
There was an exception to this rule. We found that when transparency about the prediction performance of the AI became very complex, algorithmic appreciation declined. We believe this is because the provision of too much information about the algorithm and its performance can lead to a person becoming overwhelmed with information (cognitive load). This impedes advice taking. This is because people may discount predictions when presented with too much information about the underpinning detail and they are unable or unwilling to internalize it. However, if we do not overwhelm people with information about AI then they are more likely to rely on it.
What could possibly go wrong?
If algorithms can generally make better decisions than people, and people trust them, why not rely on them systematically? Our research raises potential issues of over-confidence in machine decision-making. In some cases, the consequences of a bad decision recommended by an algorithm are minor: If a person chooses a boring film on Netflix they can simply stop watching and try something else instead. However, for high-stakes decisions that an algorithm might get wrong, questions about accountability come into play for human decision-makers. Remember the miscarriage of justice in the UK Post Office, when more than 700 Post Office workers were wrongfully convicted of theft, fraud and false accounting between 2000 and 2014, because of a fault in a computer system.
However, our research has important implications for medical diagnosis. Algorithmic advice can help where there is a patient data for examination. AI can predict with a level of likelihood whether the chances of the patient having cancer are 60% or 80% and the healthcare professional can include this information in decision making processes about treatment. This can help avoid a patient’s higher level of risk being overlooked by a human and it can lead to more effective treatment, with the potential for a better prognosis.
In wider society, algorithms can help judges in the court system make decisions that will drive a safer society. Judges can be given predictions from algorithms that present the chance of a criminal possibly committing the crime again and so decide for how long to put them away.
Methodology
To explore how and why transparency in performance influences algorithm appreciation, we conducted five controlled behavioral experiments, each time recruiting more than 400 participants via Amazon's Mechanical Turk. Across the five experiments, participants were asked to perform a prediction task in which they predict a target student’s standardized math score based on nine
pieces of information about the student before and after being presented with advice generated by the algorithmic prediction regarding the student’s predicted score.
Applications
Where firms need to make investment decisions, employees will trust AI to help inform those choices. With good data and solid, well-thought-out underlying algorithms, this has the potential to save businesses a lot of money.
Based on an interview with HEC Paris professors of Information Systems Cathy Liu Yang and Xitong Li on their paper “Algorithmic versus Human Advice: Does Presenting Prediction Performance Matter for Algorithm Appreciation,” co-written with Sangseok You, Assistant Professor of Information Systems at Sungkyunkwan University, South Korea, and published online in the Journal of Management Information Systems, 2022. This research work is partly supported by funding from the Hi! PARIS Fellowship and the French National Research Agency (ANR)'s Investissements d'Avenir LabEx Ecodec (Grant ANR-11-Labx-0047).
Many E-commerce sites such as Amazon, YouTube, and Netflix, but also online advertisers, use recommender systems. Recommender systems are algorithms that, based on data sets, recommend to users contents and products that match their preferences. In this interview, Xitong Li of HEC Paris, Associate Professor of Information Systems and a Hi! PARIS center’s research fellowship holder, reveals new research, a joint work with two German researchers, and explains how recommender systems induce consumers to buy.
Photo Credit: NaMaKuKi on Adobe Stock
What do you study?
We examine how algorithmic recommenders could induce online consumers to buy products. For example, product recommendations nowadays are widely used by online retailers, so we would like to see how showing recommendations to consumers on the online retailers’ websites would influence consumers’ consideration set, which in turns affects their purchases. By consideration set, we refer to the assortment of alternative products that consumers consider before actually making a purchase.
What recommender systems did you study?
Different types of recommender systems exist, with algorithms based on content, on collaborative filtering, or a mix of both. Collaborative filtering recommender systems are the most common in current business practices: they recommend products based on the preferences of similar users or on the similarity between products. In our study, we employed the recently developed causal mediation approach to examine the causal pathsthe underlying channel through which the use of recommender systems eventually leads to consumer purchases.
We conducted a randomized controlled field experiment on the website of an online book retailer in Europe. In the field experiment, some visitors on the online retailer’s website were randomly assigned in the treatment group to see personalized recommendations, whereas the other visitors could not see any recommendations.
Can you explain what effects of the use of personalized recommendations you observed?
Unsurprisingly, the results show that the presence of personalized recommendations increases consumers’ propensity to buy by 12.4% and basket value by 1.7%.
The presence of personalized recommendations increases consumers’ propensity to buy by 12.4% and basket value by 1.7%.
But more importantly, we find that these positive economic effects are largely mediated through influencing consumers’ consideration sets.
As explained before, a consideration set is the set of alternative products that consumers consider before making a purchase. We distinguish two aspects of a consideration set: its breadth and its depth. The breadth (also called “size”) of a consideration set refers to the number of different choices in the set, whereas the depth refers to how intensively a consumer is engaged with the choices. The depth is measured by the average number of pages viewed or the average session duration per choice before the buyer selects his final choice and purchase.
We find that the presence of personalized recommendations increases both the size and depth of consumers’ consideration set. It is these two changes that lead to the increase in consumers’ propensity to buy and the basket value.
Furthermore, we find that the effect mediated via the size of consumers’ consideration set is much stronger and significant than the effect mediated via the depth. In other words, the more choices you have taken into consideration, the more likely you will buy, and the more money you will spend.
Your findings suggest important managerial implications for professionals and practitioners. How should online retailers use recommender systems?
Now we know that consideration sets play an important role in mediating the positive effects of recommender systems on consumer purchases, online retailers need to consider the practical strategies that facilitate the formation of their considerations sets. For example, to reduce consumers’ search costs and cognitive efforts, online retailers can display the recommended products in a descending order according to the predicted similarity of consumers’ preferences. Given such a placement arrangement, consumers can quickly screen the recommended products and add the most relevant alternatives to their consideration sets, which should facilitate the consumers’ shopping process and increase shopping satisfaction.
To reduce consumers’ search costs and cognitive efforts, online retailers can display the recommended products in a descending order according to the predicted closeness of consumers’ preferences.
As recommender systems induce consumers to take more choices into consideration, it could be difficult for them to manage many choices. In other words, the more choices there are, the more difficult it is for the consumer to choose. To facilitate consumers’ shopping process, online retailers need to consider strategies and web tools that help consumers manage the choices in a better-organized manner and facilitate their comparison.
Are your findings generalizable to other contexts or business domains?
Although the field experiment in the study was conducted on the website of an online book retailer, we believe the findings are generalizable to a broader context of online retailing that uses recommender systems (Kumar and Hosanagar 2019). For example, the results can easily be applied to online retailers like Amazon and Cdiscount, as well as merchants’ online stores (e.g., Darty.com).
Interview with Xitong Li, based on his paper, "How Do Recommender Systems Lead to Consumer Purchases? A Causal Mediation Analysis of a Field Experiment", co-authored by Jörn Grahl (Head of Data Science at PHOENIX and former Professor of Information Systems, Digital Transformation and Analytics at the University of Cologne) and Oliver Hinz of the Goethe University Frankfurt, and forthcoming in Information Systems Research. Xitong Li serves as an Associate Editor on the editorial board of Information Systems Research since January 2022. He also served as a Program co-Chair for International Conference on Information Systems (ICIS) 2021. Professor Xitong Li is very open to collaborate with practitioners and help them develop innovative online retailing strategies based on big data and business analytics.
Artificial intelligence has only recently been taken on board by human resources, and only after being introduced into other fields. Where do we stand in concrete terms? Although there has been a whole host of ingenious innovations (driven on by start-ups in particular), and although everything virtual is all the rage, the technology seems to run up against serious limits when it comes to HR. Based on a survey carried out among HR managers and digitalization project managers working in major companies, I recall three potential pitfalls regarding the data used, the risk of turning AI into a gimmick, and algorithmic governance.
Photo Credit: Sittinan on Adobe Stock
What do we mean by AI?
The term artificial intelligence is polysemous, just as AI itself is polymorphic. Hidden behind AI’s vocabulary – from algorithms, conversational AI and decisional AI to machine learning, deep learning, natural language processing, chatbots, voicebots and semantic analysis – is a wide selection of techniques, and the number of practical examples is also rising fast. There’s also a distinction to be made between weak AI (non-sensitive intelligence) and strong AI (a machine endowed with consciousness, sensitivity and intellect), also called "general artificial intelligence" (a machine that can apply intelligence to any problem rather than to a specific problem). "With AI as it is at the moment, I don’t think there’s much intelligence, and not much about it is artificial... We don’t yet have AI systems that are incredibly intelligent and that have left humans behind. It’s more about how they can help and deputize for human beings" (Project manager).
AI in practice
For HR managers, AI paves the way to time and productivity savings alongside an "enhanced employee experience" (HR managers). For start-ups (and there are 600 of them innovating in HR and digital technology, including around 100 in HR and AI), the HR function is "a promising market".
Administrative and legal support: helping save time
AI relieves HR of its repetitive, time-consuming tasks, meaning that HR staff, as well as other teams and managers, can focus on more complex assignments.
Many administrative and legal help desks are turning to AI (via virtual assistants and chatbots) to respond automatically to questions asked by employees – "Where is my training application?" or "How many days off am I entitled to?" – in real time and regardless of where staff are based. AI refers questioners to the correct legal documentation or the right expert. EDF, for example, has elected to create a legal chatbot to improve its performance with users. The chatbot is responsible for the regulatory aspects of HR management: staff absences, leave, payroll and the wage policy: "We had the idea of devising a legal chatbot to stop having to answer the same legal and recurring questions, allowing lawyers to refocus on cases with greater added value. In the beginning, the chatbot included 200 items of legal knowledge, and then 800... Users are 75% satisfied with it" (Project manager).
AI can help find the correct legal documentation or the right expert, AI can check the accuracy of all declarations, AI can personalize social benefits based on employee profiles.
AI isn’t just employed for handling absences and leave or processing expense reports and training but also for the administrative and legal aspects of payroll and salary policy. For pay, AI systems can be used to issue and check the accuracy and consistency of all declarations. In another vein, AI offers packages of personalized social benefits based on employee profiles.
Recruitment: helping to choose candidates
Recruitment is another field where AI can be helpful: it can be used to simplify the search for candidates, sift through and manage applications, and identify profiles that meet the selection criteria for a given position.
Chatbots can then be used to talk to a candidate in the form of pre-recorded questions, collecting information about skills, training and previous contracts. "These bots are there to replace first-level interactions between the HR manager or employees and candidates. It frees up time so they can respond to more important issues more effectively" (Project manager).
Algorithms analyze the content of job offers semantically, targeting the CVs of applicants who are the best match for recruiters' expectations in internal and external databases via professional social networks such as LinkedIn. CV profiles that were not previously pre-selected can then be identified. Unilever has been using AI in tandem with a cognitive neuroscience approach to recruiting since 2016. Start-ups offer a service where they highlight candidate profiles without the need for CVs, diplomas or experience. Their positioning is based on affinity and predictive matching or building smart data.
These tools are aimed primarily at companies with high volumes of applications to process, such as banks for customer service positions or large retailers for departmental supervisors. Candidates are notified about the process and give their permission for their smartphone’s or computer’s microphone and camera to be activated.
These techniques appear to be efficient for low-skilled jobs and markets that are under pressure. At the same time, the more a position calls for high, complex skills, the greater the technology’s limitations.
While new practical examples are emerging over time, the views of corporate HR managers and project managers diverge regarding the added value of AI for recruitment. Some think that AI helps generate applications; identifies skills that would not have been taken into account in a traditional approach; and provides assistance when selecting candidates. Others are more circumspect: it’s possible as things stand, they argue, that people are "over promising" in terms of what AI can bring to the table.
Training and skills: personalized career paths
The AI approach to training involves a shift from acquiring business skills to customizing career paths. With the advent of learning analytics, training techniques are evolving. Data for tracking learning modes (the time needed to acquire knowledge and the level of understanding) can be used to represent the way people learn and individualize suggestions for skills development.
In addition, AI is used to offer employees opportunities for internal mobility based on their wishes, skills and the options available inside the company. AI start-ups put forward solutions for streamlining mobility management that combine assessment, training and suggestions about pathways, positions and programs for developing skills. These are limited in France, however, with the RGPD (General Data Protection Regulation), although they can be individualized in other countries.
We use AI to identify talent not detected by the HR and managerial teams; and to detect talent with a high risk of leaving the company.
Saint-Gobain has decided to use the potential of machine learning to upgrade the way it manages its talents. A project team with diverse profiles (HR, data scientists, lawyers, business lines, etc.) has been set up with two objectives: to use AI to identify talent not detected by the HR and managerial teams; and to detect talent with a high risk of leaving the company. Confidentiality is guaranteed, and no decision is delegated to machines .
Motivation and social climate: towards a better understanding of commitment
AI provides opportunities for pinpointing employees who are at risk of resigning or for improving our understanding of the social phenomena in companies.
"We’re going to ask employees questions every week or two weeks in 45 seconds on dozens of engagement levers... The responses are anonymized and aggregated, and – from another perspective – will give indicators to the various stakeholders, the head of HR, the manager, an administrator and so on. We’ll be able to tell what promotes or compromises engagement in real time while offering advice" (Project manager).
Thanks to this application, HR managers and other managers and employees can have use of real-time indicators that show the strengths and weaknesses of the teams without knowing by name who said what. “As well as helping to improve your own work and personal style, these variables mean that, if a corrective action has been put in place, you can tell what its real effect is straightaway” (HR manager).
While artificial intelligence can, as these various examples show, support human resources management, some of these new uses are still being tested.
In addition to the way they are implemented, questions and criticisms remain, including the issue of HR data, return on investment and algorithmic governance.
Data quality and restricted quantity
Data is the key ingredient for AI, and its quality is of paramount importance. If the data injected isn’t good, the results will be vague or distorted. The example of Amazon is emblematic in this respect: after launching its first recruitment software, the company decided to withdraw it quickly from the market because it tended to favor the CVs of men. In fact, the computer program Amazon used was built on resumes the company had received over the last 10 years, most of which were based on male profiles.
In addition, data sets in the field of HR tend to be narrower compared to other areas. Indeed, the number of people employed here – including in large companies – appears to be particularly low compared to the number of purchases made by customers. The quantity of sales observations for an item is very important, and big data applications can be easily performed. But there’s nothing of the sort for HR!
The quantity and quality of data needs to be considered, as well as how to embed it in a context and time interval that encourage analysis and decision-making. This is the case, for instance, in the field of predictive maintenance, where expert systems can detect signs of wear in a machine before human beings: by collecting the appropriate data, just-in-time interventions can be made to overhaul the machinery. It’s a different matter for human systems, however, where the actions and reactions of individuals are not tracked (and should they be?), and may turn out to be totally unpredictable.
Return on investment and the dangers of gimmickry
Investing in AI can be costly, with HR managers concerned about budgets and returns on investment.
"Company websites have to be revamped and modernized on a regular basis... And let's be realistic about it, making a chatbot will cost you around EUR 100,000, while redoing the corporate website will be ten times more expensive... And a chatbot is the ‘in thing’ and gives you a modern image, there’s a lot of hype, and – what’s more – it’s visible for the company! It’s something that can be seen!" (Project manager).
In many organizations, the constraints imposed by the small amount of data, and the few opportunities to iterate a process, raise the question of cost effectiveness. The HR managers we met for our study asked themselves: Should they invest in AI? Should they risk undermining the trust that employees may have in HR just to be one of the early adopters? And, although AI and virtual technology are in the limelight, are they really a priority for HR? Especially since trends come and go in quick succession: version 3.0 has barely been installed before version 4.0 and soon 5.0 come on the scene.
A further danger lies in wait for AI: the descent into gimmickry, a downward spiral which, it must be emphasized, doesn’t just threaten AI but also management tools more broadly. While the major HR software is now equipped with applications that can monitor the veritable profusion of HR indicators, isn’t there still the risk that we’ll drown in a sea of information whose relevance and effectiveness raise questions? Say yes to HR tools and no to gimmicks!
Many start-ups operating in the field of AI and HR often only have a partial view of the HR function. They suggest solutions in a specific area without always being able to integrate them into a company’s distinct ecosystem.
Photo Credit: Luca Bravo on Unsplash
"I admit I’m not very interested in the idea of becoming a beta tester, blinded by the complexity of the algorithms" (a HR manager)
Algorithmic governance
Faced with the growth in AI and the manifold solutions on offer, HR managers, aware of AI's strengths, are asking themselves: "Have I found HR professionals I can discuss things with? No. Consultants? Yes, but all too often I’ve only been given limited information, repeated from well-known business cases that don’t really mean I know where I‘m setting foot... As for artificial intelligence, I’ve got to say, I haven't come across it. Based on these observations, I admit I’m not very interested in the idea of becoming a beta tester, blinded by the complexity of the algorithms and without any real ability to compare the accuracy of the outcomes that these applications would give me. Should we risk our qualities and optimal functioning, not to mention the trust our employees put in us, just to be among the early adopters?" (HR manager).
Society as a whole is defined by its infinite diversity and lack of stability. Wouldn’t automating management and decision-making in HR fly in the face of this reality, which is both psychological and sociological? The unpredictability of human behavior cannot be captured in data. With AI, don’t we risk replacing management, analysis and informed choices with an automatism that destroys the vitality of innovation?
What room would there then be for managerial inventiveness and creativity, which are so important when dealing with specific management issues? While the questions asked in HR are universal (how can we recruit, evaluate and motivate…?), the answers are always local. The art of management cannot, in fact, be divorced from its context.
Ultimately, the challenge is not to sacrifice managerial methods but to capitalize on advances in technology to encourage a holistic, innovative vision of the HR function where AI will definitely play a larger role in the future, especially for analyzing predictive data.
See also: Chevalier F (2023), “Artificial Intelligence and Human Resources Management: Practices and Questions” in Monod E, Buono AF, Yuewei Jiang (ed) Digital Transformation: Organizational Challenges and Management Transformation Methods, Research in Management, Information Age Publishing.
"AI and Human Resources Management: Practices, Questions and Challenges", AOM Academy of Management Conference, August 5-9, 2022, Seattle, USA.
This article presents a summary of “Intelligence Artificielle et Management des Ressources Humaines: pratiques d’entreprises”, Enjeux numériques, No. 15 (September 2021) by Françoise Chevalier and Cécile Dejoux. This research is supported by a grant of the French National Research Agency (ANR), “Investissements d’Avenir” (LabEx Ecodec/ANR-11-LABX-0047).
What comes out of our collaborations with artificial intelligence? What happens in the minds of humans who are involved in interactions with smart non-humans? Does AI change how we come up with new ideas and work together on bringing them into life? Daria Morozova, Ph.D. student at HEC Paris’s Management and Human Resources department, explains how her research on AI-human interactions can help establish best practices for creative work involving artificial intelligence.
While many may think creativity will be a key human capacity as work processes get increasingly automated, AI-applications get more creative as well: for example, AI-painted portraits sell at exorbitant prices, pop hits feature AI-generated music, and mainstream media ‘hire’ AI-journalists to publish thousands of articles a week. How workplace AI-application will impact creative processes, crucial for innovation and organizational development, is an important question that needs rigorous scientific attention.
What can research bring to the field of creativity with AI?
Research can help find ways to foster creative work and innovation augmented by the numerous AI-provided capacities. We need research that explains how we can create and adapt artificial agents and arrange working processes such that employees do not have to be defensive against AI and be more creative.
By now, we have learned that many people believe that artificial agents – these are, for instance, AI-run apps like Siri or Alexa, or social robots you may see at an airport - are not suited for creative work or work that requires diplomacy and judgement skills. So, normally people would not care much about AI trying to compose a symphony or write a novel as long as they believe that humans are creatively superior. But we also know that when AI is involved in creative work – for example, generating image suggestions, or even creating logotypes at a design studio, people often reject its results and evaluate them lower even if the AI objectively performs just as well as a human.
This is a problem because when employees believe that AI should not be creative and it turns out to be exactly that, they may feel threatened by it, fearing it might substitute them, and these feelings are normally not very conducive to creativity. In addition, when threatened, employees will try to protect themselves – after all, we want to feel that we, humans, the creative species, are unique. This hence may also hinder creative work.
How can your research help manage creative human-AI interactions?
Together with my advisor Professor Mathis Schulte, we investigate the differences in how people work on creative and non-creative tasks when they collaborate with AI, compete with it, or use results of its work as a benchmark for their own performance. We also investigate how these interactions are different from same situations in which a human counterpart is involved instead of an AI agent.
Creative interactions with AI is a nascent area of managerial knowledge, and we are excited to be making first contributions to it. We show, for instance, that people use the same psychological mechanisms in comparing themselves to AI agents, even when they believe these agents can’t really compete with people creatively. We also show that what we believe about ourselves and about AI matters, and while some beliefs can make employees work harder on creative tasks, other may demotivate them. Knowing what these configurations are will help managers set up collaborations such that AI is used to its full capacity, and people blossom in creative work.
We show, for instance, that people use the same psychological mechanisms in comparing themselves to AI agents, even when they believe these agents can’t really compete with people creatively.
So, what main differences do you find between human-human and human-AI creative interactions?
First of all, we saw that people did not take as much time to work on a creative task – that is, they were not as effortful - when they collaborated with an AI as when they collaborated with a colleague. This was not the case for a non-creative task, in which people worked on average for the same time both with an AI and a human collaborator. To illustrate, in one of our experiments, the creative task was to come up with recycling ideas for a medical mask (this task could be, for example, a challenge in an engineering competition, or a topic for an entertaining article, which was the setting in our experiment). The non-creative task was to find recycling-related words in a word matrix that needed to be tested as a game for publishing online.
Word search matrix
People were not as effortful to work on a creative task when they collaborated with an AI as when they collaborated with a colleague.
We also found that an AI’s performance did not matter for such a decrease in effort. In a different experiment, we asked the participants to propose ideas on how to motivate their colleagues to move more or to eat better. We then showed them either a list of nonsense ideas (which really was a text generated by an algorithm!) or a list of sensible ideas. We told the participants that the list they see was either created by an AI or by someone else who also participated in the experiment. As a result, some people saw a nonsense list of ideas and thought it was proposed by an AI, and others thought that same list was suggested by a human. Regarding the list of sensible ideas, a third group saw a sensible list that was ostensibly AI-written, and the last group thought it was a human suggestion. Then, we again asked the participants to propose ideas on one of the topics. We found that no matter whether the ideas made sense or not, participants who looked at ideas that were introduced as suggested by other people took almost half a minute longer on the second task than those who thought the ideas were AI-generated.
Interestingly, this was also the case in the non-creative task, in which participants looked for a specific character on an old-Russian birch bark, looked at the results of work of an AI or a human, and looked for another character again. Although we did not expect them to, participants who saw the results of AI’s work, both done well and failed, took less time to work on the task in the second round.
Participants looked for a specific character on an old-Russian birch bark”. (Original birch bark from “Histrf” website)
Birch bark in which the counterpart did the task well.
Birch bark in which the counterpart failed the task.
The results of these two experiments suggest that in many cases, especially when we think AI has no place in creative work, we might be less motivated to exert effort on it than we do when working together with another human.
In many cases, we might be less motivated to exert effort on creative work when there is AI participation, than we do when working together with another human.
So what are the conditions in which AI can motivate us try harder on a creative task?
This we tackled in a further experiment. In it, we again had participants think about creative ideas for the use of a medical mask or medical gloves. But, unlike in the first experiment, we first subtly made half of the participants remember that creativity is what makes humans unique, while the other half did not see such a reminder. We also told the participants that either an AI or a person came up either with many creative ideas, or with only a few. The results of these manipulations were astounding: while people who were reminded that creativity is a uniquely human trait and saw that AI came up with 20 ideas worked on average for almost full five minutes, those who were also reminded of creativity uniqueness but saw that it was a person that thought of 20 ideas took only 3.5 minutes to work on the task. We also saw that when high creative performance of AI was unexpected, people were much more threatened by that AI.
What are the implications of these findings for practice?
These findings have very important implications for practice: what should we tell employees about AI-applications that can be used in creative work to not have them disengage as they have nothing to prove against supposedly non-creative AI? How do we motivate them to perform creatively without scaring them with AI? These are the questions that I am looking forward to solving in my future work.
You’re using some unusual online services to conduct your research. Can you describe how you recruit your participants and why these services are so attractive?
People who participated in these experiments were recruited either on Prolific, which is a rather popular British service for academic research, or on Yandex.Toloka, which is a Russian service for recruitment of individual workers on mini-tasks like data markup.
Using both platforms is a great advantage. First, I can test whether the effects I hypothesize are universal across different cultures and nationalities. Second, as specialized platforms have recently been criticized for data quality, people that I recruit at Yandex.Toloka, which is primarily used by businesses for crowdsourcing, are naïve to experimental studies and, as the majority of these tasks are quite mechanical and dull, they are intrinsically motivated to participate in my experiments – I have received quite a few messages from participants saying that they enjoyed the “task” and would be willing to do it again. Although, unfortunately for these participants, that will not be possible to not compromise the integrity of the research, I think it says much about how people are unlikely to sabotage participation.
I can test whether the effects I hypothesize are universal across different cultures and nationalities.
Finally, Yandex.Toloka offers a great gender balance in the sample (51% of participants I randomly recruit there are women), people come from different walks of life and mostly have had quite a lot of working experience – their average age is almost 36 years. These factors make the use of both services a great strength of my research design, and I thank GREGHEC Laboratory for enabling me to use them by providing research support in the form of funding that got me almost 1200 participants.
HEC Paris Assistant Professor in Marketing, Klaus Miller, analyzes the February 3 Facebook/Meta stock market plunge. What exactly does it tell us about private data on internet and its links to the advertising world? We meet Klaus on February 8, the very day he and five co-researchers self-published “The Impact of the GDPR on the Online Advertising Market”. This book focuses on Europe’s GDPR and how it affects online publicity. In a wide-ranging discussion on personal data and the advertising industry, Klaus provides insights on ad blockers on news websites and their impact on our reading habits.
Klaus Miller, Assistant Professor of Marketing at HEC Paris
Listen to the podcast:
External content from Acast has been blocked.
Access privacy settings
In January, you published a major research paper on the impact of ad blockers on the consumption of news . Some are attributing the fall in Meta’s stock prices on February 3 partly to changes in both Europe’s and Apple’s privacy regulations. Mark Zuckerberg himself admitted: “There is a clear trend where less data is available to deliver personalized ads.” Specialists believe this trend partly explains Meta’s 23% drop in stock value. Your analysis of this argument?
Let us take a step back on this question. What we as a society (and essentially our data protection agencies and regulators) are facing is the trade-off between protecting consumer privacy, on the one hand, and fostering economic prosperity of firms, on the other. And we have seen very different regimes across the globe answering this question in very different ways. For example, in the United States, the balance has always tilted towards more economic prosperity and less data protection of the users. And in Europe we have taken a different approach, whereby we want more privacy protection and we accept higher costs or less prosperity for firms. However, we can see several changes in consumer behavior that are now affecting Meta/Facebook specifically.
Apple allowed its iPhone users to choose whether advertisers could track them. Three-quarters said no, according to the analytics company Flurry. How is this affecting advertisers?
Indeed, with regards to Apple, every app developer within the iOS network has to ask his or her app users for consent to being tracked. And this has led to many users not consenting to this tracking, which makes it more difficult for firms such as Facebook. They rely heavily on iOS devices for their revenue, collecting personal data to target consumer with personalized advertising.
Advertising money is essentially shifting towards Google search advertising because firms who rely heavily on iOS devices such as Facebook are facing low consent rates and thus lower revenues as they are less able to target consumers with personalized advertising
So what happens if you take away online tracking? That's basically the big question. What we see is that advertising money is essentially shifting towards Google search advertising, towards Android, and away from iOS app advertising. This has a major impact on Facebook because they are highly reliant on iOS and mobile advertising revenues in general.
One of your research projects studied the activities of almost 80,000 users on a news website. The results indicate an impressive leap of consumption of news by those using ad blocks. What conclusions can you draw from this?
Basically, what we found in our research paper, “How Does the Adoption of Ad Blockers Affect News Consumption?”, is that ad-sensitive users consume up to one third more content when not seeing ads. Their behavior is transformed. There's a group of users that really hate ads, to be frank. And I think it’s very important for publishers to recognize this, especially if you consider the large number of ad blocker users are younger audiences. Our data find that, on average, 24% of all users use an ad blocker. But if you look at the younger target groups, they're up to 100% ad blocker usage. Again, I think it is very important for publishers to recognize this finding that younger target groups do not want to be monetized by seeing annoying advertising.
We find that ad-sensitive users consume up to 1/3 more content when not seeing ads, and that 24% of all users use an ad blocker. I think publishers should recognize this.
A major issue facing companies that use AI, algorithmic bias can perpetuate social inequalities — as well as pose legal and reputational risks to the companies in question. New research at HEC Paris offers a statistical method of tracking down and eliminating unfairness.
Soon after Apple issued its Apple credit card, in August 2019, urgent questions arose. A well-known software developer and author, David Heinemeier Hansson, reported in a Tweet that both he and his wife had applied for the card. “My wife and I filed joint tax returns, live in a community-property state, and have been married for a long time,” Hansson wrote. “Yet Apple’s black box algorithm thinks I deserve 20x the credit limit she does.” He called it a “sexist program,” adding an expletive for good measure.
Goldman Sachs, the issuing bank for the credit card, defended it, saying that the AI algorithm used to make determinations of creditworthiness didn’t even take gender into account. Sounds convincing, except that this ignored the fact that even if specific gender information is removed, algorithms may still use inputs that correlate with gender (“proxies” for gender, such as where a person shops) and thus may still produce unintended cases of bias.
Even Apple’s cofounder Steve Wozniak reported that he and his wife had experienced this bias. Wozniak was judged worthy of 10 times more credit than his wife, despite the fact that he and his wife shared assets and bank accounts. The ensuing melee resulted in an investigation of the Apple Card’s algorithm by New York regulators.
Biased data leads to biased results
AI/machine learning can process larger quantities of data more efficiently than humans. If applied properly, AI has the potential to eliminate discrimination against certain societal groups. However, in reality, cases of algorithmic bias are not uncommon, as seen in the case of Apple, above.
If a credit-scoring algorithm is trained on a biased dataset of past decisions by humans, the algorithm would inherit and perpetuate human biases.
The reasons for this bias are various. If, for example, a credit-scoring algorithm is trained on a biased dataset of past decisions by humans (racist or sexist credit officers, for example), the algorithm would inherit and perpetuate human biases. Because AI uses thousands of data points and obscure methods of decision making (sometimes described as a black box), the algorithmic biases may be entirely unintended and go undetected.
In credit markets — the focus of our work — this lack of fairness can place groups that are underprivileged (because of their gender, race, citizenship or religion) at a systemic disadvantage. Certain groups could be unreasonably denied loans, or offered loans at unfavorable interest rates — or given low credit limits. A lack of fairness may also expose the financial institutions using these algorithms to legal and reputational risk.
A “traffic light” test for detecting unfair algorithms
My fellow researchers, Christophe Hurlin and Sebastien Saurin, and I established a statistics-based definition of fairness as well as a way to test for it. To ensure fairness, decisions made by an algorithm should be driven only by those attributes that are related to the target variables, such as employment duration or credit history, but should be independent of gender, for example. Using statistical theory, we derived a formula to compute fairness statistics as well as the theoretical threshold above which a decision would be considered fair.
We established a statistics-based definition of fairness as well as a way to test for it.
When dealing with an actual algorithm, one can first compute the fairness statistics and compare them to the theoretical value or threshold. It is then possible to conclude whether an algorithm is “green” (when the fairness statistics are greater than our established threshold) or “red” (when the fairness statistics are less than the threshold).
Second, if there is a problem, we offer techniques to detect the variables creating the problem — even if the algorithm’s processes are impenetrable. To do so, we developed new AI explainability tools. Third, we suggest ways to mitigate the problem by removing the offending variables.
We developed new AI explainability tools to detect the variables creating the problem of unfairness.
From a purely practical, business perspective, it is important that banks understand the implications — and potential unintended consequences — of the technology they are using. They may risk running afoul of both the justice system and public opinion — and it goes without saying that reputation and trust are key in the banking industry.
Application across diverse fields
While our focus has been on credit scoring, our methodology could potentially be applied in many other contexts in which machine learning algorithms are employed, such as predictive justice (sentencing, probation), hiring decisions (screening of applicants’ CVs and videos), fraud detection and pricing of insurance policies.
The use of machine learning technology raises many ethical, legal and regulatory questions. When machine learning techniques, which are often difficult to interpret, are poorly applied, they can generate unintended, unseen bias toward entire populations on the basis of ethnic, religious, sexual, racial or social criteria. The opportunities and risks that come with machine learning techniques undoubtedly call for the implementation of a new form of regulation based on the certification of the algorithms and data used by companies and institutions.
In the short term, we aim to help companies and institutions that use AI to better understand the decisions of their algorithms and to detect potential unintended consequences. In the longer term, we hope to contribute to the discussion about guidelines, standards and regulations that public administrators should institute.
Methodology
Drawing on work conducted over 15 years on risk model validation, we developed new statistical tests that detect a lack of fairness. This “traffic light” test statistically analyzes whether an algorithm’s decisions are fair (“green”) or unfair (“red”) against protected societal groups. If an algorithm’s decisions are found to be unfair, we suggest techniques to identify the variables responsible for the bias and to mitigate them.
According to recent research published by the Harvard Business Review, a strong privacy policy can help firms save millions. If privacy policies have indeed become more important for firms and consumers today, the real challenge lying ahead is to ensure compliance within and beyond the firm. A new tool developed at HEC Paris uses artificial intelligence to help managers, data protection officers, and project leaders take privacy-preserving decisions and implement privacy by design.
In the back end of privacy policies, a firm needs to ensure its own processes and those of its supply chain are in line with privacy regulations, so what is presented to consumers in the front end through privacy policies is realistic and effective.
A new tool, using artificial intelligence methods, including machine learning, builds on a year-long effort and is currently under test with industrial partners. It was developed by a multi-stakeholder initiative led by HEC Paris Professor David Restrepo Amariles, Aurore Troussel (LL.M. HEC. 19), and Rajaa El Hamdani, data scientists at HEC Paris.
Think back to the last time you signed up for a new website or online service. Did you read the terms and conditions before you clicked “accept”? If the answer to that question is an embarrassed “no”, then don’t worry, you are not alone. The length and the vocabulary used in most of privacy documents make data processing of companies time-consuming and difficult to understand. Researchers at HEC Paris developed Privatech, a new machine-learning powered application which detects breaches to General Data Protection Regulation (GDPR) in privacy documents.
Researchers at HEC Paris developed Privatech, a new machine-learning powered application which detects breaches to GDPR in privacy documents.
This application could serve consumers, lawyers, data protection officers, legal departments, and managers in auditing the privacy documents of a company. But more importantly, it aims to further generate privacy compliance in the back end of data flows, or in other words, to ensure companies are informed of data practices so they can take privacy preserving decisions. Privatech allows managers who are not specialized in privacy protection to conduct a preliminary compliance assessment and detect potential issues requiring specialized advice.
Privatech allows managers who are not specialized in privacy protection to conduct a preliminary compliance assessment and detect potential issues requiring specialized advice.
The challenge for businesses: complying with EU (and US) law
The General Data Protection Regulation came into force in 2018 and many companies saw this regulation as a challenge in terms of compliance. In 2017, 90% of executives consider GDPR to be the most difficult form of compliance to achieve1. GDPR requires companies to govern their data processing while ensuring data subject’s rights. Under GDPR, companies have to set up procedures and documents enabling users to access clear information about their personal data processing and to control this processing.
The cost of non-compliance is estimated to be 2.71 times the cost of compliance.
Two aspects of GDPR are of particular importance for businesses. First, GDPR has a very broad application’s scope, far outside EU borders. Second, GDPR sets forth fines of up to 10 million euros or up to 2% of the company’s entire global turnover, whichever is higher. It explains why the cost of non-compliance is estimated to be 2.71 times the cost of compliance2. In addition, the recent entry into force of the California Consumer Privacy Act (CCPA) shows that the data processing of companies will be more and more scrutinized by regulators. This regulatory trend makes investment in privacy compliance technologies relevant.
An app built with a coalition of law and business
Privatech uses machine learning to automate the process of complying with legislation. With the help of several law firms and companies including Atos, one of the largest IT companies in Europe, HEC Paris researchers created a tool for automating the assessment of privacy policies.
The tool can read privacy policies and detect lines that might not be compliant with the law or may leave consumers' personal data open to exploitation.
This means the tool can read privacy policies and detect lines that might not be compliant with the law or may leave consumers' personal data open to exploitation. To develop this tool, researchers relied on annotated privacy policies, with clauses’ labels corresponding to different data practices, and connected these annotations to corresponding GDPR articles and obligations.
Data practices are categories of data processing activities, for example “data retention” which is a data practice that refers to how long data can be stored. Each paragraph in the privacy policies was tagged to a corresponding data practice. We then trained a machine-learning algorithm to identify and label different data practices in a legal document. The app also assesses readability of privacy policies because a key aspect of GDPR requires privacy policies to be easily readable. The app is calibrated so that all text should be readable by any high-school student.
Reshaping privacy compliance from the ground up
Privatech aims to streamline privacy compliance and consumer protection by focusing on firms (data controllers and processors) rather than on consumers (data subjects). The application may help individuals to better understand the privacy policies that they would otherwise sign blindly. However, we decided to focus on companies as they could generate privacy compliance by design and are liable under GDPR.
By focusing on firms, Privatech aims to ensure companies are able to translate privacy policies disclosed to consumers into effective corporate compliance mechanisms. We expect that Privatech will eventually encourage companies to design and monitor their data processing activities, so they are legal, comprehensive and easy to understand.
Applications
Our work will be valuable for any companies and data handlers who have a need to comply with data protection legislation. The project will reduce the need for the repetitive and labour-intensive elements of legal assessment of privacy documents and improve compliance with legislation. Our work will also be valuable for consumers who may struggle to interpret privacy documentation such as GDPR. Ultimately, data protection authorities could also use the application to conduct audits and monitor compliance with GDPR.
Methodology
The project started as a class deliverable for two courses offered by Professor David Restrepo at HEC Paris, TechLaw offered in the LL.M program, and Data Law and Technology Compliance offered in the MSc Data Science for Business jointly organized by HEC Paris and Ecole Polytechnique. A first beta version relied on the students’ work and collaboration from lawyers at Baker McKenzie Paris and tech entrepreneurs, including Croatian developer Vedran Grčić. Since August 2019 the project is fully developed in-house at HEC Paris by the Smart law Hub, which integrates law scholars and data scientists.
The project has also changed its methodology and focus. The application is developed to detect unlawful or problematic sentences within privacy policies and to evaluate the complexity of privacy documents.
The algorithms have been trained on data retrieved by researchers. The training data set is composed of sentences retrieved from various privacy policies, and judicial and administrative decisions. These sentences were labelled and categorized by data practices such as “data retention” or “data sharing”. This preparatory work allowed for the creation of a machine-learning algorithm able to identify and label different data practices in a legal document.
In addition, a readability algorithm evaluates the complexity of privacy document to verify its compliance with transparency and explainability requirements. The main focus of the research today is compliance generation which seeks to monitor internal documents and documents in the data supply chain.
Have you been enraged by a chatbot recently? Businesses from Starbucks to LinkedIn and Singapore Airlines to eBay are embracing AI-powered communication tools. But the success of using chatbots to streamline operations and deliver consistent, round-the-clock customer support hinges on gaining user trust, show recent findings from HEC Paris Professor Shirish Srivastava and his co-authors Dr. Shalini Chandra of the SP Jain School of Global Management, Singapore and Dr. Anuragini Shirish of the Institut Mines Telecom Business School, France.
Microsoft launched its ChatGPT-powered search engine chatbot earlier this year. Within three months of its release, the Bing chatbot has engaged in over half a billion chats, has over 100 million active daily users, and app downloads have increased fourfold. Since Microsoft's paperclip assistant, Clippy, first hit our screens in 1995, we've been trying to make computers more human-like, in order to smooth the often-awkward interface between the biological brain and synthetic software.
Adoption rates of conversational AI tools could more than double over the next five years, but the success of the Bing chatbot and others like it hinges on user acceptance and engagement. Many people are still uncomfortable using this technology, find it unfit for purpose, or unable to empathize and understand their needs. When computer pioneer Alan Turing conceived the "imitation game" 70 years ago, he understood that our demand for AI to think in a way that was indistinguishable from a human would be vital to its adoption.
In a world where 86% of customers still prefer humans to chatbots for online interactions, we wanted to explore how businesses could improve user engagement with chatbots.
Testing out three chatbots for their humanness
We recruited around 200 people with little to no experience with chatbots and presented them with Mitsuku, Bus Uncle, and Woebot.
Mitsuku (now known as Kuki) is designed to befriend humans in the metaverse, taking the form of an 18-year-old female. Able to chat, play games and do magic tricks at the user's request, Mitsuku is said to have inspired the movie Her and is a five-time winner of a Turing Test competition called the Loebner Prize. Woebot is designed to be a mental health support. The chatbot describes itself as a charming robot friend and uses AI to offer emotional support through talk therapy, as a friend would. And Bus Uncle is used across Singapore to tell users about bus arrival timings and deliver public transport navigation, supposedly with the “personality of a real uncle.”
We collected data on the individual characteristics of our respondents and their general perceptions of chatbots. Next, we gave the study respondents time with one of the three chatbots. We then asked them about their experience with it. For a different perspective, we also conducted ten interviews with frequent chatbot users about their interactions and experiences.
What human-like competencies in chatbots foster user engagement?
To foster user engagement, chatbots must create a natural, human-like interpersonal environment that enables natural, engaged communication. We must learn to program AI to deal with more intricate tasks, using humanized social skills to query, reason, plan, and solve problems. But which aspects of human behavior should be prioritized when designing conversational AI programs?
AI designers should be aware that building believable, human-like qualities into conversational AI is as important as improving its efficiency.
We looked at media naturalness theory (MNT), which suggests that face-to-face communication is the most natural and preferred form of human communication. The theory suggests that three main mechanisms govern how natural, smooth, and engaging interaction with technology feels:
A decrease in cognitive effort, i.e., the amount of mental activity a user expends communicating with the technology,
A reduction in communication ambiguities, i.e., misinterpretations and confusion in how the user interprets the messages,
An increase in physiological arousal, i.e., the emotions that users derive from interacting with the technology.
Translating these ideas into the context of chatbots, we came up with three competencies we thought such AI would need to engage users:
Cognitive competency – the ability of chatbots to consider and apply their problem-solving and decision-making skills to the task at hand in creative, open-minded, and spontaneous way.
Relational competency – the AI agent’s interpersonal skills, such as supporting, cooperating, and collaborating with its users, appearing cooperative and considerate.
Emotional competency – AI’s ability to self-manage and moderate interactions with users, accounting for their moods, feelings, and reactions by displaying human warmth and compassion.
Through our research, we have confirmed that cognitive and emotional competency builds user trust and engagement. This was less clear for relational competency because chatbots do not yet have the skills to remember previous interactions to build relationships and readjust appropriately to the task demanded. Though the importance of relational competency was confirmed by the qualitative interview study in our mixed methods research, we learnt that most chatbots do not offer enough opportunities to develop relational competency. This is a rich area for future research.
How important is users' trust in their engagement with chatbots?
We proposed that user trust in chatbots is the central mechanism that mediates the relationship between human-like interactional competencies in AI and user engagement with conversational AI agents.
Prior research has shown that trust in technology influences its use and take-up across contexts such as m-commerce portals, business information systems, and knowledge management systems. We also know that users are more likely to trust interactive technologies with human-like features such as voice and animation. Such trust is expected to be more pronounced in the case of AI-driven customer interactions because as they interact with it, users can constantly gauge the AI's value in terms of its human-like attributes as it responds to their different queries and responses.
Our findings show that human-like cognitive and emotional competencies serve as innate trust-building mechanisms for fostering user engagement with chatbots.
We asked 200 people with little to no experience with interactional AI about their perceptions of chatbots, asked them to interact with one, and then interviewed them to ask about their experiences with it. For a different perspective, we also conducted ten interviews with frequent chatbot users about their interactional experiences.
Applications
AI designers should be aware that building believable, human-like qualities into conversational AI is as important as improving its efficiency. And to boost use customer engagement, organizations need to prioritize giving chatbots cognitive capabilities that closely align with how we as humans think. They should design these tools to understand and respond to the spectrum of human emotions, providing appropriate responses and making decisions in response, such as redirecting customers to live service agents during frustrated exchanges. AI practitioners and designers should also consider ways to increase relational competency in conversational AI agents and chatbots by introducing relatable human attributes.
Based on an interview with Professor Shirish C Srivastava on his HEC Foundation-funded research “To Be or Not to Be… Human? Theorizing the Role of Human-Like Competencies in Conversational Artificial Intelligence Agents,” co-written with Dr Shalini Chandra from the S P Jain School of Global Management in Singapore and Dr Anuragini Shirish from Institut Mines-Télécom Business School in Paris, published in the Journal of Management Information Systems, December 2022. This research has been selected to receive funding from the HEC Foundation's donors.
A new study developed by Thomas Åstebro, Professor of Entrepreneurship at HEC Paris, finds that the number of private equity (PE) and venture capital (VC) firms using artificial intelligence has increased dramatically in the past decade. The study claims that while increasing efficiency overall, AI will also change deal-making processes and destroy junior-level jobs. This article summarizes the article, ‘An Inside Peek at AI Use in Private Equity’, published in the Journal of Financial Data Science (Summer 2021, jfds.2021.1.067) with Portfolio Management Research (PMR).
Photo Credits: lidiia on Adobe Stock
In my research, I interviewed members of the executive suite at a few PE/VC firms and had some descriptive data analysis performed to forecast the evolution of the industry. I find that the increased usage of Artificial Intelligence (AI) in Private Equity and Venture Capital will boost the sector’s operational efficiency greatly and transform the ways in which partners perform their work. However, it will also lead a technological arms race and cause an eventual industry shakeout.
An increased use of AI will have a substantial impact on the sector both positively and negatively. For example, my paper points out beneficial changes such as reducing travel and meetings, increasing long-distance deals, diversifying investment portfolios, and encouraging the launch of new PE/VC firms. Together, these efficiencies will completely re-design PE/VC firms’ workflows and deal-making processes. However, the paper also points out that the increased use of AI systems will likely eliminate junior-level tasks, and cause loss of jobs.
One of the companies analysed for the paper is Jolt Capital, a company which has seen a quick rise in operational efficiency after the introduction of AI in its decision-making processes. At Jolt Capital, the AI-based decision support system learns to imitate the preferences and decisions of experienced partners in the form of “likes” and distributes that experience to help all those involved at the firm. Jean Schmitt, the firm’s CEO explains: “the learning part is critical, because after a while, the system can tell me what I like and what I don’t like. A junior isn’t filtering these deals; my digital self is.”
I believe that AI adoption by established PE/VC firms is expected to accelerate, first by incorporating AI piecemeal into various tasks, and later completely disrupting old ways of thinking and working. It is expected that we will continue to see the entry of new firms that specialize in using AI. PE/VC firms are always trying to beat one another to the punch. Predictably, they will increasingly do so, driven by a technological arms race. However, the expansion of new firms based on AI also will have clear negative competitive effects.
As most industries that experience a radical business-transforming innovation such as this one demonstrates, the increased competition focused on new technology will eventually squeeze out new entrants and accelerate the exit of those that cannot remain at the technological frontier. This dynamic typically leads to industry shakeouts.
















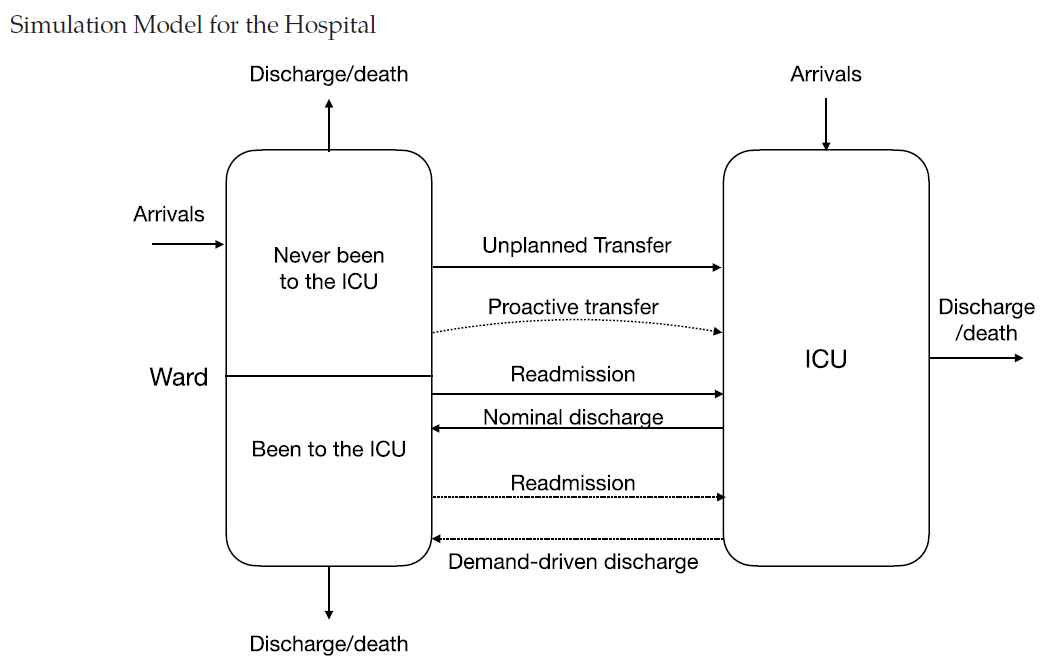














































.jpg){kind=link}